ANOVA à mesures répétées en utilisant les modèles mixtes
Ce tutoriel explique comment calculer et interpréter une ANOVA à mesures répétées avec les modèles mixtes avec Excel en utilisant XLSTAT
Jeu de données pour réaliser une ANOVA à mesures répétées avec les modèles mixtes
Les données ont été obtenues sur un échantillon de 24 patients en dépression séparés en deux groupes (1 : contrôle / 2 : traitement). Cinq mesures ont été effectuées sur les patients (0 : avant le début du traitement, 1 : 1 mois après le début du traitement, 3 : 3 mois après et 6 : 6 mois après). La variable dépendante représente un score permettant d’évaluer l’état de dépression du patient.
Une ANOVA à mesures répétées est basée sur le même modèle qu’une ANOVA classique, dans notre cas, l’équation du modèle s’écrira : ![]()
On aura donc deux facteurs fixes (les variables group et time) et un facteur d’interaction. La différence avec une analyse de la variance classique réside dans le fait que les erreurs eijk pourront être corrélées. En effet, nous ne pouvons pas supposer que les mesures sur un même sujet prises à des périodes différentes soient indépendantes.
XLSTAT utilise les modèles mixtes afin de faire une ANOVA sur mesures répétées. Ceci entraîne quelques différences avec l’ANOVA sur mesures répétées classique. Des options supplémentaires sont présentes, par exemple, l’utilisation de différentes structures sur la matrice de covariance des erreurs. Dans ce tutoriel, nous utiliserons la structure compound symmetry. Pour obtenir des détails sur les structures de covariance, veuillez consulter l’aide d’XLSTAT.
Le format des données :
Les données doivent être sous un format bien particulier dans le cas de l’utilisation d’une ANOVA sur mesures répétées avec les modèles mixtes, on aura : - une variable qualitative mesures répétées qui indiquera la mesure à laquelle on se trouve - une variable qualitative sujet qui indiquera le sujet traité
Ainsi, dans notre exemple ; chaque individu (sujet) apparaîtra dans quatre lignes. La figure suivante résume le format utilisé (on aura donc 4 colonnes et 96 lignes):

Ainsi, si vos données sont au format : une colonne par mesure, il faudra modifier ce format de façon à obtenir le format précédent.
Paramétrer une ANOVA à mesures répétées avec les modèles mixtes
Une fois XLSTAT lancé et les données dans le bon format, choisissez la commande XLSTAT / Modélisation / ANOVA à mesures répétées ou cliquez sur le bouton ANOVA à mesures répétées de la barre d'outils Modélisation.
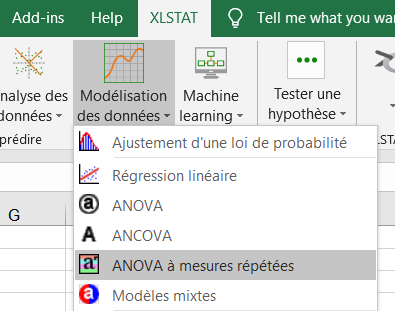
Une fois le bouton cliqué, la boîte de dialogue correspondant à l'ANOVA à mesures répétées apparaît. Dans le premier onglet, vous pouvez sélectionner les données sur la feuille Excel.
La Variable dépendante correspond à la variable expliquée (ou variable à modéliser), qui est dans ce cas précis le score (dv). Toutes les variables restantes sont qualitatives, sélectionnez les 3 variables "subj", "time" et "group".
L'option Libellés des variables est laissée activée car la première ligne des colonnes comprend le nom des variables.
Les variables sujet et répétée doivent être aussi sélectionnées parmi les variables explicatives.
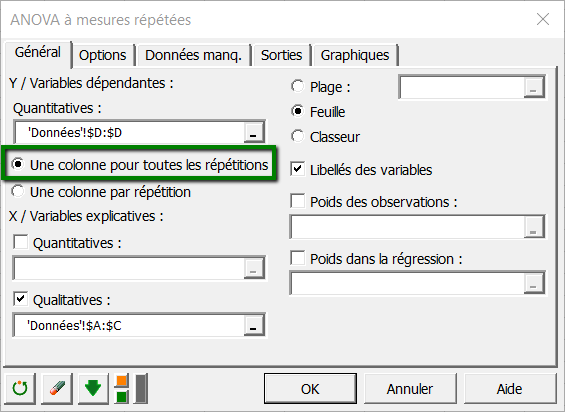
Dans l'onglet Options, vous pouvez sélectionner la structure de la matrice de covariance des erreurs (pour des détails sur les options de cet onglet, voir l’aide d’XLSTAT).
Sélectionnez la structure compound symmetry. Nous choisissons la contrainte a1=0, ce qui implique que le modèle s'écrira de façon à considérer que le groupe des contrôles (group=1) aura l'effet de base.
Appliquer une contrainte en ANOVA est indispensable pour des raisons théoriques, mais cela ne change ni les résultats, ni la qualité de l'analyse.
Par ailleurs, nous allons prendre en compte des interactions, il faut donc activer l’option interactions.
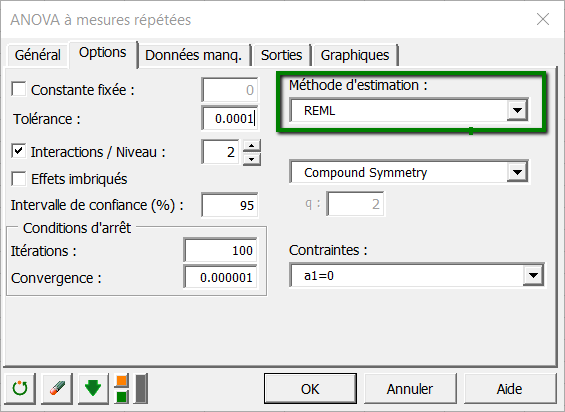
Une fois que l'utilisateur a cliqué sur OK, une nouvelle fenêtre permettant de sélectionner les facteurs fixes, la variable répétée et la variable sujet apparaît :
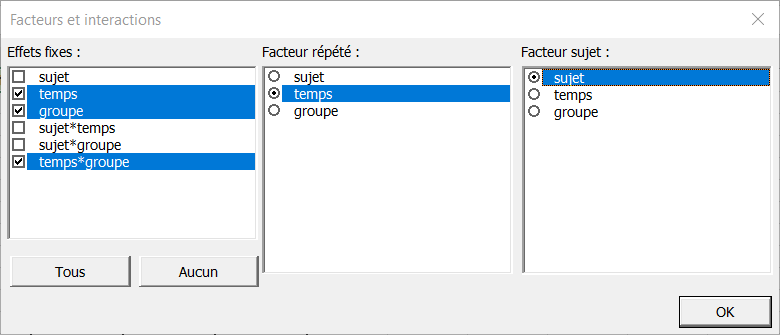 Nous voulons effectuer une ANOVA à mesures répétées en utilisant comme effets fixes les variables "time", "group" et "time*group".
Nous voulons effectuer une ANOVA à mesures répétées en utilisant comme effets fixes les variables "time", "group" et "time*group".
Le facteur répété est la variable "time". Le facteur associé aux sujets est la variable "subj" qui est associé au numéro du patient traité.
Note : XLSTAT ne permet pas de définir un facteur simultanément comme effet fixe et comme facteur sujet. Les variables associées au facteur répété et au facteur sujet doivent être différentes et doivent être qualitatives.
Une fois que l'utilisateur a cliqué sur OK, les calculs reprennent et les résultats sont affichés.
Interpréter une ANOVA à mesures répétées avec les modèles mixtes
Le premier tableau de résultats fournit les coefficients d'ajustement ainsi que des informations associés aux données.
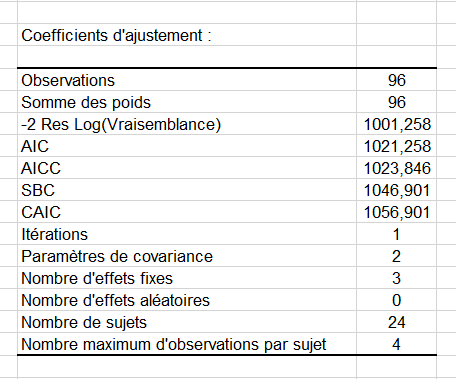
Les coefficients du modèle sont obtenus en utilisant le maximum de vraisemblance restreint (REML), on obtient donc des indices différents de ceux de l’ANOVA classique. Les AIC, AICC, SBC et CAIC sont des indices qui permettent de comparer des modèles en utilisant différentes structures de matrices de covariance.
Le tableau suivant donne les paramètres de la matrice de covariance des erreurs (structure compound symmetry). Il y a ici deux paramètres estimés et tous deux sont significatifs.
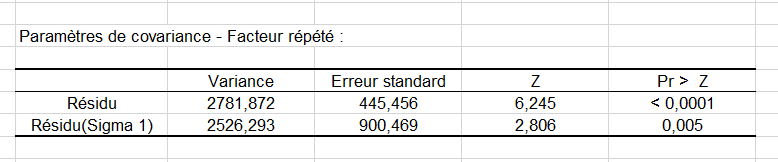
Les résultats du test du rapport des vraisemblances permet de comparer le modèle classique lorsqu’on suppose que les mesures associées au même sujet à des moments différents sont indépendantes (matrice de covariance des erreurs diagonale) et le modèle avec la structure de covariance sélectionnée.

Nous voyons que la différence est significative et que l’on gagne donc à utiliser la structure compound symmetry. Nous voulons maintenant savoir si les variables contribuent toutes autant à expliquer la variabilité. Pour cela nous devons analyser les tableaux de résultats des tests de type III des effets fixes. Ces résultats sont équivalents aux Type III SS de l’ANOVA classique.
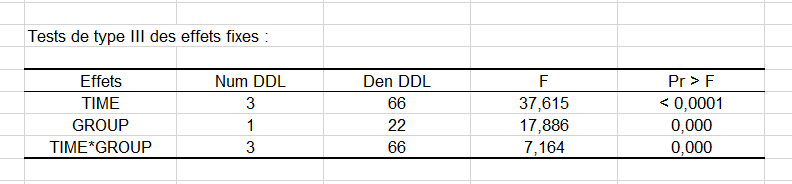
Le tableau des tests de type III des effets fixes permet de vérifier la significativité des effets fixes en utilisant un test F de Fisher. Nous voyons donc que tous les effets fixes sont significatifs. Le temps écoulé a l’effet le plus important.
Ainsi, nous pouvons donc dire que le traitement et le temps écoulé ont des effets sur les patients Le tableau suivant rassemble les paramètres du modèle, leur écart-type ainsi qu’un intervalle de confiance. Ces paramètres s’interprètent de la même façon que dans le cas d’une analyse de la variance classique.
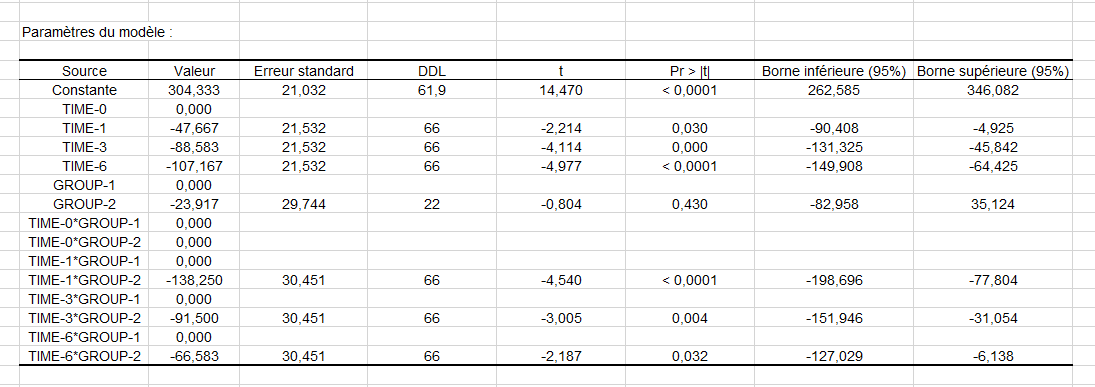
En analysant les paramètres du modèle, on voit qu'aux temps 1, 3 et 6, l’effet sur le score est négatif et que le fait d’être traité a un effet négatif sur le score. Le tableau ci-dessus peut être utilisé pour étudier l'impact des variables sur le score, mais aussi pour prédire des valeurs dans des situations qui n'on pas été rencontrées. Ainsi, d'après le modèle, on peut déterminer qu’un patient traité aura un score moyen de 107,1 au temps 6, tout en sachant que l'influence de l'interaction ne peut être prise en compte.
Ainsi, nous avons pu étudier un modèle d’ANOVA en prenant en compte le fait que certaines observations n’étaient pas indépendantes. D’autres sorties sont disponibles dans XLSTAT et nous permettront d’approfondir l'analyse comme, par exemple, les différents types de résidus ainsi que les graphiques associés aux résidus et aux moyennes obtenues par moindres carrés.
Cet article vous a t-il été utile ?
- Oui
- Non