PLS-PM : analyser la satisfaction des consommateurs dans Excel
Ce tutoriel vous permet d'utiliser l'approche PLS pour analyser la satisfaction dans le domaine du marketing avec Excel et XLSTAT. L'approche PLS est une alternative aux modèles d'équations structurelles.
Le principe de l’approche PLS
L’approche PLS est une méthode statistique permettant de modéliser des relations complexes entre des variables observées et des variables latentes. Ce type de modèles est généralement appelé modèle d’équations structurelles à variables latentes. L’approche PLS privilégie la recherche d’une optimalité prédictive des relations plutôt que celle de relations de causalité. Plutôt que de valider un modèle en termes de qualité d’ajustement, on utilisera des indices de qualité prédictive. Pour plus de détails sur ces points, on peut voir l’aide de XLSTAT et deux articles de référence sur le sujet : Chin (1998, plutôt orienté vers les applications) et Tenenhaus et al. (2005, plutôt orienté vers la théorie). L’approche PLS du fait qu’elle calcule des scores pour les variables latentes est très utile dans le calcul d’indices globaux, le plus connu d’entre eux étant l’indice de satisfaction des consommateurs.
L’approche PLS avec XLSTAT-PLSPM
Dans ce tutoriel, nous vous guidons afin de créer un projet, définir un modèle, estimer les paramètres de celui-ci et analyser les résultats dans le cadre de l’analyse de la satisfaction des consommateurs. L’application présentée est basée sur des données réelles. 250 clients d’un opérateur de téléphones portables ont été contactés afin de répondre à un grand nombre de questions pour pouvoir modéliser leur fidélité envers l’opérateur. Le modèle PLSPM est basé sur l’indice de satisfaction européen des clients (ECSI). Ce modèle à variables latentes est représenté dans la figure suivante :

Chaque variable latente est reliée à un certain nombre de variables manifestes qui sont directement observables et donc mesurées. Dans cette application, les variables manifestes sont mesurées sur des échelles de 0 à 100. Par exemple, pour la variable latente image, les cinq variables manifestes associées sont :
- on peut avoir confiance en ce qu’il fait et dit
- c’est un opérateur stable et bien implanté
- c’est un opérateur qui apporte une contribution sociale à notre société
- c’est un opérateur pour lequel les clients sont importants
- c’est un opérateur innovant
Jeu de données pour appliquer l’approche PLS en analyse de la satisfaction
Les projets XLSTAT-PLSPM sont des classeurs Excel spécifiques. Lorsqu’un nouveau projet est créé, il prend le nom PLSPMBook. Il est possible ensuite de le sauver, mais il faut bien utiliser la commande de sauvegarde de la barre XLSTAT-PLSPM afin de la sauvegarder en entier avec l’extension *.ppmx. De plus, au moment de la création une boîte de dialogue vous permettra de sélectionner le mode d’affichage. Dans le cadre de l’analyse de la satisfaction, nous utilisons le mode market qui simplifiera les boîtes de dialogue et les sorties. Note : il peut arriver que lorsqu’on ouvre le fichier, l’affichage soit mal organisé. Il suffit de cliquer sur « Optimiser l’affichage » (voir plus loin). Un projet XLSTAT-PLSPM vierge contient deux feuilles qui ne peuvent pas être supprimées : - D1 : feuille de calcul vide dans laquelle il faut copier les données que l’on veut traiter. - PLSPMGraph : Feuille blanche utilisée pour dessiner le modèle. Lorsque cette feuille est sélectionnée, la barre d’outils apparaît. Si vous ouvrez un projet déjà créé, vous pouvez changer le mode d’affichage à tout moment en cliquant sur options PLSPM dans le menu PLSPM du ruban.

Dans le cadre de ce tutoriel, nous nous focaliserons sur l’affichage market qui permet d’appliquer l’approche PLS dans les cas d’analyse de la satisfaction des consommateurs. Nous sauvons maintenant le projet en utilisant la fonction « enregistrer le projet sous ».
Attention, il faut toujours sauvegarder et ouvrir les projets .ppmx en utilisant les fonctions PLSPM et non les fonctions classiques d’Excel.
Nous copions les données d’une feuille classique Excel vers la feuille D1. On peut alors mettre en place le modèle. Allez vers la feuille PLSPMGraph. La barre de commandes se trouve en haut à gauche :

Afin de créer plusieurs variables latentes à la suite, double-cliquez sur le bouton dédié, de façon à ce qu’il reste enfoncé : 
Vous pouvez alors ajouter les flèches reliant les variables latentes les unes aux autres. Pour ajouter une flèche, il suffit de cliquer sur la variable latente de laquelle elle part et de sélectionner la variable latente de destination en gardant appuyer le bouton CtrL. Une fois les deux variables sélectionnées, utilisez soit le bouton de la barre d’outil comme dans la figure suivante, soit le raccourci clavier Ctrl+L.

Une autre méthode vous permet de charger des modèles prédéfinis, en utilisant le septième bouton, vous pourrez charger un modèle depuis une bibliothèque, vous arriverez alors sur un répertoire dans lequel des modèles renommés sont disponibles. En sélectionnant l’un de ces modèles, il sera automatiquement importé dans votre projet. Les modèles ont l’extension .ppmxmod.
Une fois que tous les liens ont été ajoutés ou que le modèle structurel a été chargé, il faut définir les variables manifestes associées à chaque variable latente. La manière la plus rapide consiste à cliquer sur la variable latente et utilisez le bouton MV de la barre :

Ceci active une boîte de dialogue qui s’ouvre sur la feuille D1. Cette boîte permet de donner un nom à la variable latente, définir les variables manifestes et mettre en place quelques options de base.
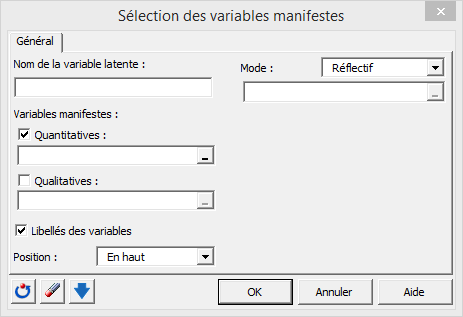
Ce menu permet de définir chacun des blocs de variables manifestes en sélectionnant les données dans la feuille de calcul D1. On doit aussi choisir le mode d’estimation : dans le cadre de cette application nous supposons que les construit sont réflectifs et sélectionnons donc le mode A. Dans le mode A, les variables manifestes sont des reflets de la variable latente, c’est le cas réflectif. Dans le mode B, les variables manifestes construisent la variable latente, c’est le cas formatif.
Par exemple, pour la variable latente Attente, la boîte de dialogue aura la forme suivante :

Le modèle obtenu a la forme suivante :

Une fois l’ensemble du modèle construit, on peut lancer l’application de l’approche PLS en utilisant la barre d’outils et en cliquant sur Lancer les calculs :

La boîte de dialogue lancer les calculs apparaît :
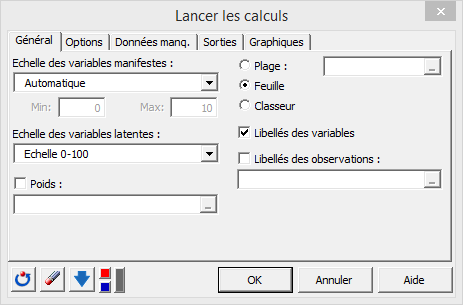
Dans notre application, on utilise le mode automatique pour les échelles des variables manifestes. L’échelle des variables latentes est choisie entre 0 et 100. Les options sont laissées par défaut et on ne modifie que les sorties.

Nous activons l’option tableau de simulation et sélectionnons la variable latente à expliquer satisfaction car nous voulons étudier l’impact d’un changement des variables du modèle sur la satisfaction. L’ordre de grandeur de ce changement est mesuré en pourcentage et va de -10% à 10% par pas de 1%. Nous activons aussi les tableaux IPMA (Importance Performance Matrix Analysis).
Résultats et interprétation des sorties d’un projet PLSPM
La première partie des résultats rassemble des informations sur les données et le modèle créé (statistiques descriptives des variables manifestes, spécification du modèle).
Le premier élément important est la vérification de l’unidimensionnalité des blocs. Nous nous trouvons dans le cas réflectif, les blocs doivent donc être unidimensionnels. On utilise donc le tableau donnant la fiabilité des blocs :

On peut voir que l’alpha de Cronbach est en-dessous de son seuil (0,7) pour les variables Attente et Fidélité. Néanmoins, le rho de Dillon et Goldstein est toujours supérieur à 0,7. Finalement, la première valeur propre est beaucoup plus grande que la seconde dans beaucoup de cas. Ces résultats nous poussent à considérer que les blocs sont unidimensionnels même si une analyse des dimensions supplémentaires de l’attente et de la fidélité pourrait être intéressante. Par ailleurs, les indices n’apparaissent pas pour la variable latente Réclamations car elle ne possède qu’une seule variable manifeste associée.
La sortie suivante est le tableau des GoF qui permettent d’évaluer la qualité d’ajustement du modèle :

On voit que le GoF absolu est de 0,484, très proche de son estimation bootstrap. Cette valeur est difficile à interpréter et sert surtout afin de comparer différents groupes d’individus ou différents modèles. Le Gof relatif et ceux basés sur les modèles internes et externes sont très élevés et auraient tendance à traduire une bonne qualité d’ajustement du modèle aux données. Deux tableaux détaillent les poids externes et les corrélations associées au modèle de mesure.
Une fois le modèle de mesure étudié, le modèle structurel peut être analysé. Pour chaque variable latente, un certain nombre d’informations sont rassemblées. Nous prenons l’exemple de la satisfaction :

Ainsi, avec un R² de 0,681, on peut considérer que la variable latente est bien expliquée. On voit que c’est la qualité perçue qui a le plus fort impact sur la satisfaction suivie par la valeur perçue. L’impact des attentes est non significatif. Le dernier tableau résume l’ensemble des résultats précédents. On voit que la qualité perçue contribue à 59 % du R².
Le graphe suivant illustre les résultats précédents :
 Ensuite les sorties liées à l’analyse marketing peuvent être trouvées. On trouve d’abord les IPMA (Importance Performance Matrix Analysis) qui permettent de visualiser l’importance et la performance de variables latentes sur une variable cible. Si on regarde la satisfaction, nous avons :
Ensuite les sorties liées à l’analyse marketing peuvent être trouvées. On trouve d’abord les IPMA (Importance Performance Matrix Analysis) qui permettent de visualiser l’importance et la performance de variables latentes sur une variable cible. Si on regarde la satisfaction, nous avons :
 On voit que la qualité est la plus importante et la plus performante. Il sera difficile d’augmenter la performance de cette variable latente sachant que celle-ci est déjà élevée. Ensuite viennent les attentes et l’image qui ont la même importance. L’image semble intéressante car sa performance est plus faible et pourra sûrement être améliorée plus facilement.
On voit que la qualité est la plus importante et la plus performante. Il sera difficile d’augmenter la performance de cette variable latente sachant que celle-ci est déjà élevée. Ensuite viennent les attentes et l’image qui ont la même importance. L’image semble intéressante car sa performance est plus faible et pourra sûrement être améliorée plus facilement.
Ensuite sont présentés les graphiques de simulation. Tout d’abord pour les variables manifestes. Le premier graphique résume l’effet d’une augmentation de X% d’une variable manifeste sur la satisfaction. On voit pour 10% les résultats sont les suivants :

On voit que c’est la variable QUALITY5 qui a l’effet le plus fort. Le graphique suivant est équivalent au précédent à la différence que l’on part de la valeur de la moyenne.
On étudie ensuite des changements sur les variables latentes :
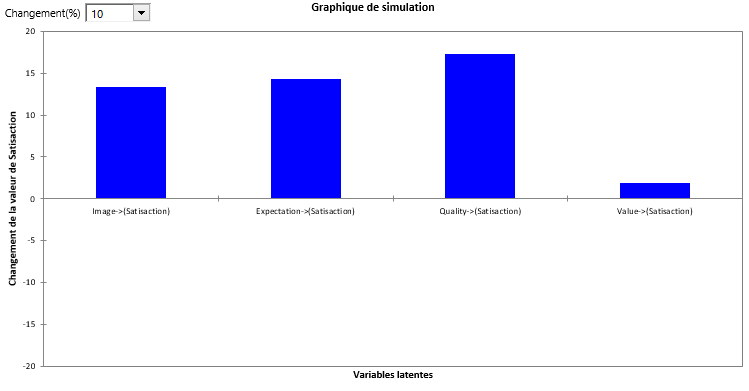
On voit ici qu’une augmentation de 10% de la qualité entraînera une augmentation de près de 17% de la satisfaction. Le même graphique basé sur les moyennes est ensuite affiché.
Dans la suite des sorties sont rassemblés les scores des variables latentes et les statistiques descriptives associées. Ces scores peuvent être réutilisés dans le cadre d’autres analyses statistiques avec XLSTAT.
Pour conclure
Cette analyse nous a permis de présenter l’étude d’un jeu de données sur un modèle de satisfaction. Nous avons illustré l’utilisation de l’approche PLS qui permet de comprendre des interactions entre des concepts de manière claire. Une fois que le modèle est validé, il est simple d’interpréter les coefficients afin d’analyser les résultats.
Cet article vous a t-il été utile ?
- Oui
- Non