Apprentissage d'une Machine à vecteurs de support (SVM) dans Excel
Ce tutoriel vous aidera à mettre en place et entraîner un classifieur par Machines à Vecteurs de Support (SVM) dans Excel en utilisant le logiciel de statistiques XLSTAT.
Jeu de données pour entrainer un classifieur SVM
Le jeu de données utilisé dans ce tutoriel est extrait de la compétition de Machine Learning intitulé Titanic: Machine Learning from Disaster sur Kaggle, la fameuse plateforme de data science.
Le jeu de données du Titanic est accessible à cette adresse. Il fait référence au naufrage du fameux paquebot le Titanic en 1912. Au cours de cette tragédie, plus de 1500 des 2224 passagers trouvèrent la mort en partie à cause d'un nombre insuffisant de canots de survie.
Le jeu de données en question est constitué d'une liste de 1209 passagers et des informations suivantes : - Survived : le passager a survécu (0 = Non; 1 = Oui)
- Pclass : Classe voyage (1 = 1ère; 2 = 2nde; 3 = 3ème)
- Name : Nom
- Sex : Genre (homme ; femme)
- Age : Age
- Sibs : Nombre de frères et soeurs / épouses à bord
- Parch : Nombre de parents / enfants à bord
- Fare : Tarif pour le passager
- Cabin : Cabine
- Embarked : Port d'embarquement (C = Cherbourg; Q = Queenstown; S = Southampton)
Objectif de ce tutoriel
L'objectif de ce tutoriel est d'apprendre à mettre en place et entrainer un classifier SVM sur le jeu de données Titanic pour voir les performances que nous obtenons sur un jeu de données de validation.
Mettre en place un classifieur SVM dans Excel avec XLSTAT
Pour mettre en place un classifieur SVM, cliquez sur Machine Learning / Machine à vecteurs de support comme indiqué ci-dessous :
 Une fois que vous avez cliqué sur le bouton, la boîte de dialogue SVM apparait. Sélectionnez les données dans la feuille Excel. Dans le champ intitulé variable réponse, sélectionnez la variable binaire que vous souhaitez prédire. Dans notre cas, c'est la colonne donnant l'information de survie du passager.
Une fois que vous avez cliqué sur le bouton, la boîte de dialogue SVM apparait. Sélectionnez les données dans la feuille Excel. Dans le champ intitulé variable réponse, sélectionnez la variable binaire que vous souhaitez prédire. Dans notre cas, c'est la colonne donnant l'information de survie du passager.
Il faut également sélectionner des variables explicatives quantitatives et qualitatives en activant les deux options comme indiqué ci-dessous.
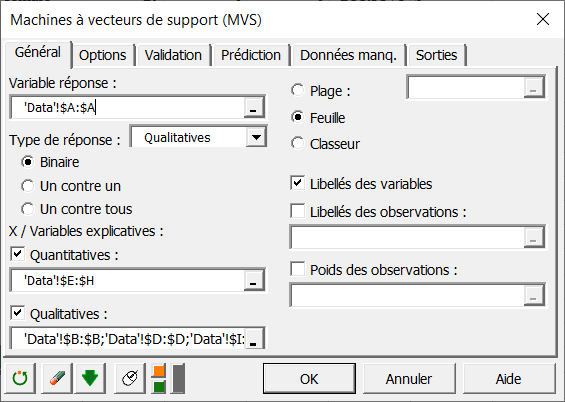 Dans le champ Quantitatives, sélectionnez les colonnes suivantes : - age
Dans le champ Quantitatives, sélectionnez les colonnes suivantes : - age
- sibsp
- parch
- fare
Pour sélectionner plusieurs colonnes, utilisez la touche Ctrl de votre clavier. Dans le champ Qualitatives, sélectionnez les colonnes avec les informations qualitatives : - pclass
- sex
- embarked
Comme le nom de chaque variable est présent au début du fichier, assurez-vous que la case Libellés des variables est cochée.
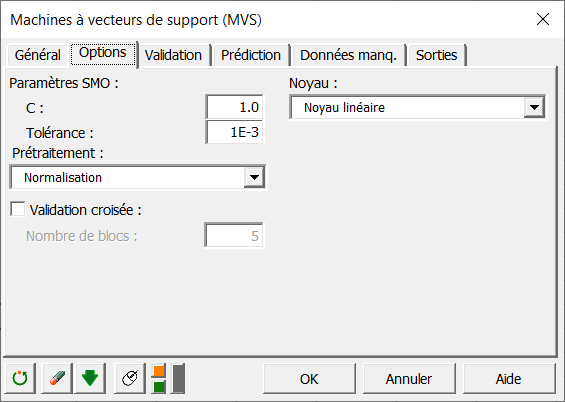
Dans l'onglet Options, vous pouvez régler les paramètres du classifieur. Pour les paramètres SMO, le champ C correspond à la variable de régularisation. Elle traduit le niveau de mauvaises classifications que vous souhaitez autoriser durant l'optimisation. Une grande valeur de C signifie une forte pénalité pour chaque observation mal classée. Dans notre cas, nous réglons ce paramètre à 1.
Le paramètre de tolérance indique le niveau de précision souhaité durant l'optimisation. Pour accélérer les calculs, vous pouvez augmenter la valeur de ce paramètre. Nous le laissons à sa valeur par défaut.
Pour le prétraitement, nous choisissons normalisation et nous utiliserons des noyaux linéaires comme indiqué ci-dessous.
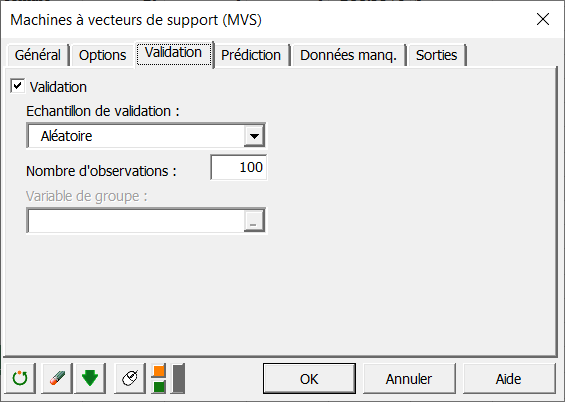
 Comme nous voulons voir les performances de notre classifieur, nous allons créer un échantillon de validation à partir de jeu d'apprentissage. Pour cela, dans l'onglet validation, nous cochons la case validation et sélectionnons 100 observations prises aléatoirement dans l'échantillon d'apprentissage :
Comme nous voulons voir les performances de notre classifieur, nous allons créer un échantillon de validation à partir de jeu d'apprentissage. Pour cela, dans l'onglet validation, nous cochons la case validation et sélectionnons 100 observations prises aléatoirement dans l'échantillon d'apprentissage :
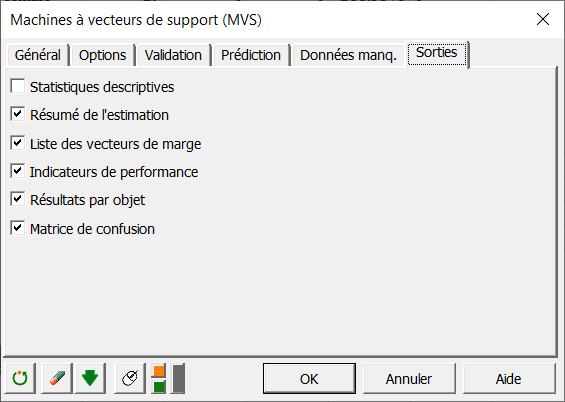
 Finalement, dans l'onglet des sorties, sélectionner les sorties comme indiqué ci-dessous:
Finalement, dans l'onglet des sorties, sélectionner les sorties comme indiqué ci-dessous:
 Les calculs démarrent lorsque vous cliquez sur OK. Les résultats sont ensuite affichés.
Les calculs démarrent lorsque vous cliquez sur OK. Les résultats sont ensuite affichés.
Interpréter les résultats d'une classification SVM
Le premier tableau donne un résumé des caractéristiques du classifieur obtenu. Vous pouvez voir sur la figure ci-dessous que le classifieur devait classer les niveaux 0 et 1 et que le niveau 0 a été marqué comme la classe positive. Il y a eu 943 observations utilisées pour entrainer le classifieur, parmi celles-ci, 452 ont été identifiées comme vecteurs de support.
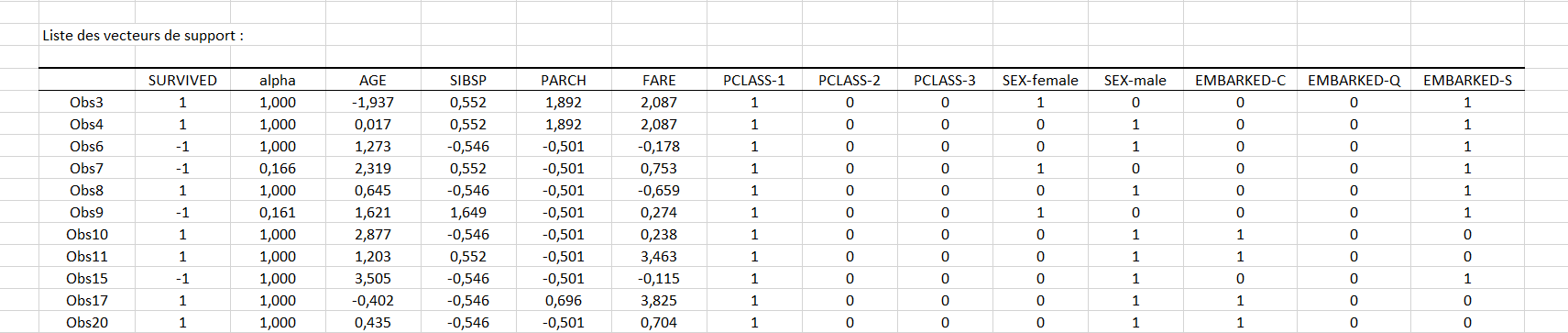
 Le second tableau montré ci-dessous donne la liste complète des 452 vecteurs de support avec le coefficient alpha associé et la valeur positive ou négative de la classe de sortie. Ces derniers avec la valeur du biais donnée dans le tableau précédent suffisent à décrire complètement le classifieur optimisé.
Le second tableau montré ci-dessous donne la liste complète des 452 vecteurs de support avec le coefficient alpha associé et la valeur positive ou négative de la classe de sortie. Ces derniers avec la valeur du biais donnée dans le tableau précédent suffisent à décrire complètement le classifieur optimisé.
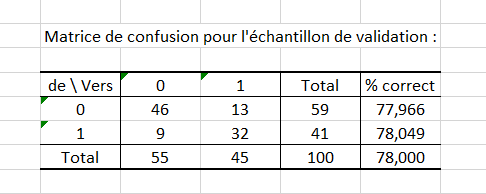
 Le tableau suivant donne la matrice de confusion obtenues sur l’échantillon de validation. Elle donne le niveau de performance de notre classifieur. Nous obtenons 78% de réponses correctes pour le jeu de validation.
Le tableau suivant donne la matrice de confusion obtenues sur l’échantillon de validation. Elle donne le niveau de performance de notre classifieur. Nous obtenons 78% de réponses correctes pour le jeu de validation.
 À la suite de ce tableau, nous retrouvons la courbe ROC associée à l’échantillon de validation. La courbe ROC correspond à la représentation graphique du couple (1 – spécificité ; sensibilité) pour les différentes valeurs seuil.
À la suite de ce tableau, nous retrouvons la courbe ROC associée à l’échantillon de validation. La courbe ROC correspond à la représentation graphique du couple (1 – spécificité ; sensibilité) pour les différentes valeurs seuil.
Nous cherchons à avoir une courbe qui s’approche du coin supérieur gauche, ce qui est le cas ici :
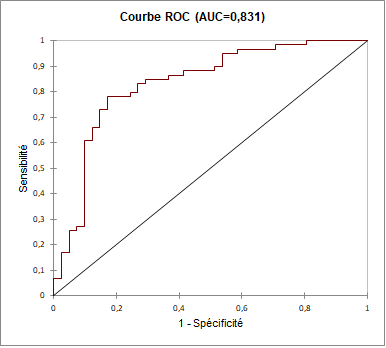 Enfin, l’aire sous la courbe ROC, qu’on appelle AUC est de 83,1%. Cela signifie que le modèle a 83,1% de chance de bien classer une observation de la classe positive.
Enfin, l’aire sous la courbe ROC, qu’on appelle AUC est de 83,1%. Cela signifie que le modèle a 83,1% de chance de bien classer une observation de la classe positive.
Conclusion sur la classification SVM
Nous avons entrainé notre classifieur en utilisant des noyaux linéaires et obtenu un résultat raisonnablement bon de 78% de réponses correctes. Des réglages supplémentaires restent cependant encore nécessaires pour challenger les meilleurs data scientist sur kaggle! Une approche possible serait de tester une autre famille de noyaux pour voir comment un plus grand nombre de dimensions peut aider à améliorer les performances de notre classifieur.
Cet article vous a t-il été utile ?
- Oui
- Non