Training a Support Vector Machine (SVM) in Excel
Dieses Tutorium wird Ihnen helfen, einen Support Vektor Machine (SVM)-Klassifikator in Excel mithilfe der Software XLSTAT einzurichten und zu trainieren.
Datensatz für das Training eines SVM-Klassifikators
Der Titanic-Datensatz kann unter folgender Adresse abgerufen werden (https://www.kaggle.com/c/titanic). Es bezieht sich auf das Sinken der RMS Titanic im Jahre 1912. Während dieser Tragödie verloren mehr als 1.500 der 2.224 Passagiere ihr Leben aufgrund einer unzureichenden Anzahl von Rettungsbooten.
Der Datensatz besteht aus einer Liste von 1209 Passagieren und einigen Informationen: - survived: Überleben (0 = Nein; 1 = Ja)
- pclass: Passagierklasse (1 = 1st; 2 = 2nd; 3 = 3rd)
- name: Name
- sex: Geschlecht (männlich; weiblich)
- age: Alter
- sibsp: nzahl von Geschwistern/Eheleuten an Bord
- parch: Anzahl von Eltern/Kindern an Bord
- fare: Passagier-Reisepreis
- cabin: Kabine
- embarked: Einschiffungshafen (C = Cherbourg; Q = Queenstown; S = Southampton)
Absicht dieses Tutoriums
Die Absicht dieses Tutoriums besteht darin, zu lernen, wie ein SVM-Klassifikator im Titanic-Datensatz eingerichtet und trainiert wird und wie gut der Klassifikator in einem Datensatz zur Validierung funktioniert.
Erstellen eines SVM-Klassifikators
Zum Erstellen eines SVM-Klassifikators klicken Sie auf Maschinelles Lernen/Machine Support Vector gemäß der nachstehenden Abbildung:
 Sobald Sie auf den Button gedrückt haben, erscheint das Dialogfenster SVM. Markieren Sie die Daten in dem Excel-Tabellenblatt.
Sobald Sie auf den Button gedrückt haben, erscheint das Dialogfenster SVM. Markieren Sie die Daten in dem Excel-Tabellenblatt.
Im Feld Antwortvariable wählen Sie die binäre Variable, die wir beim Klassifizieren unserer Daten vorhersagen möchten. In unserem Fall liefert diese Spalte die Überlebensinformationen.
Wir wählen außerdem sowohl quantitative als auch qualitative erklärende Variablen, indem wir beide Kontrollkästchen wie unten gezeigt markieren.
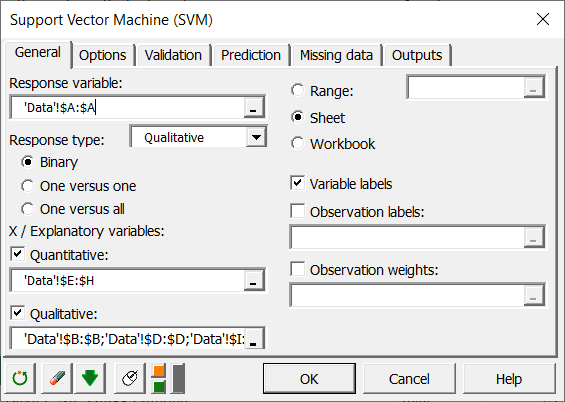 Im Feld quantitativ wählen wir Spalten entsprechend den folgenden Feldern aus: - age
Im Feld quantitativ wählen wir Spalten entsprechend den folgenden Feldern aus: - age
- sibsp
- parch
- fare
Zum Auswählen mehrerer Spalten können Sie die Taste Strg-Taste verwenden.
Im Feld qualitativ wählen wir die Spalten mit qualitativen Informationen: - pclass
- sex
- embarked
Da der Name jeder Variablen oben in der Tabelle angezeigt wird, müssen wir das Kontrollkästchen Variablenbeschriftungen markieren.
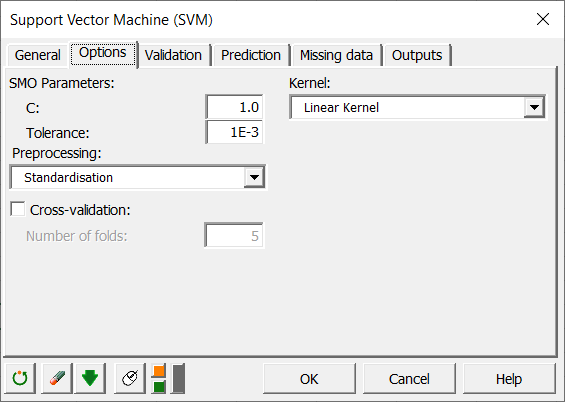
In der Registerkarte Optionen müssen die Klassifikator-Parameter eingerichtet werden. Für die SMO-Parameter übernehmen wir die Standardoptionen. Das Feld C entspricht dem Regularisierungsparameter. Es übersetzt, wieviel Missklassifikation Sie während der Optimierung zulassen möchten. Ein großer Wert C bedeutet eine hohe Strafe für jede missklassifizierte Beobachtung. In unserem Fall setzen wir den Wert C auf 1. Das Feld Epsilon ist ein numerischer Präzisionsparameter. Es ist rechnerabhängig und kann bei 1e-12 gelassen werden. Der Toleranzparameter sagt aus, wie genau der Optimierungsalgorithmus beim Vergleichen von Support-Vektoren sein wird. Wenn Sie die Berechnungen beschleunigen möchten, können Sie die Toleranzparameter erhöhen. Wir lassen die Toleranz bei ihrem Vorgabewert.
Wir wählen das Feld Neu skalieren bei der Vorbearbeitung und wir verwenden lineare Kernels wie unten dargestellt.
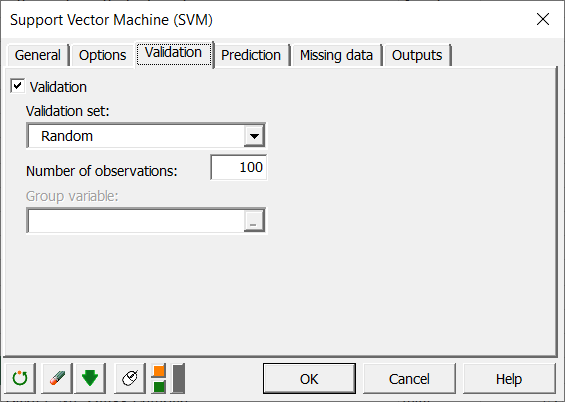
 Da wir sehen wollen, wie gut unser Klassifikator funktioniert, erstellen wir eine Validierungsstichprobe aus der Trainings-Stichprobe. Zu diesem Zweck markieren wir in der Registerkarte Validierung das Kontrollkästchen Validierung und wählen 100 Beobachtungen aus, die zufällig aus der Trainings-Stichprobe gezogen wurden, wie nachfolgend gezeigt.
Da wir sehen wollen, wie gut unser Klassifikator funktioniert, erstellen wir eine Validierungsstichprobe aus der Trainings-Stichprobe. Zu diesem Zweck markieren wir in der Registerkarte Validierung das Kontrollkästchen Validierung und wählen 100 Beobachtungen aus, die zufällig aus der Trainings-Stichprobe gezogen wurden, wie nachfolgend gezeigt.
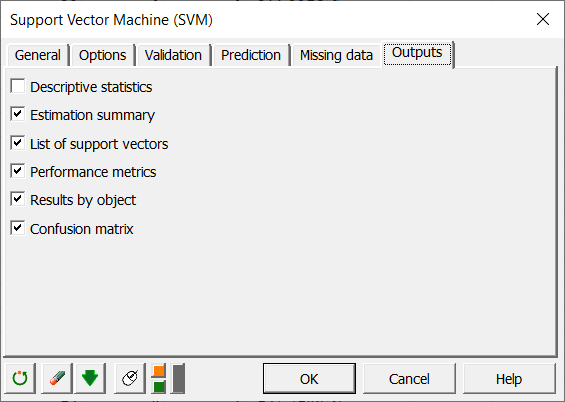
 Schließlich wählen wir in der Registerkarte Ausgabe die Ausgaben, die wir erhalten möchten, gemäß der folgenden Darstellung aus:
Schließlich wählen wir in der Registerkarte Ausgabe die Ausgaben, die wir erhalten möchten, gemäß der folgenden Darstellung aus:
 Die Berechnungen beginnen, sobald Sie auf OK geklickt haben. Die Ergebnisse werden dann angezeigt.
Die Berechnungen beginnen, sobald Sie auf OK geklickt haben. Die Ergebnisse werden dann angezeigt.
Interpretieren der Ergebnisse des SVM-Klassifikators
Die erste Tabelle zeigt eine Zusammenfassung des optimierten SVM-Klassifikators an. Sie können in der nachstehenden Abbildung sehen, dass der Klassifikator zwischen den Klassen 0 und 1 klassifizieren musste, und dass die Klasse 0 als positive Klasse bezeichnet wurde. Es gab 943 Beobachtungen, die für das Training des Klassifikators verwendet wurden, aus denen 456 Support-Vektoren identifiziert wurden.
 Die nachstehend gezeigte zweite Tabelle liefert die vollständige Liste der 456 Support-Vektoren mit den verbundenen alpha-Koeffizientwerten und dem positiven oder negativen Wert der Ausgabeklasse. Zusammen mit dem Verzerrungswert der ersten Tabelle reichen diese Informationen aus, um den optimierten Klassifikator vollständig zu beschreiben
Die nachstehend gezeigte zweite Tabelle liefert die vollständige Liste der 456 Support-Vektoren mit den verbundenen alpha-Koeffizientwerten und dem positiven oder negativen Wert der Ausgabeklasse. Zusammen mit dem Verzerrungswert der ersten Tabelle reichen diese Informationen aus, um den optimierten Klassifikator vollständig zu beschreiben
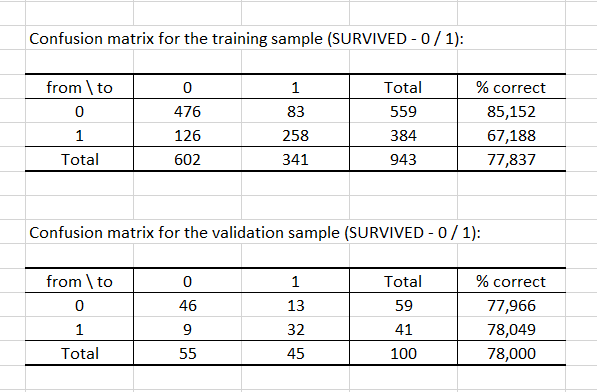
 Die nächsten beiden Tabellen zeigen die resultierenden Konfusionsmatrizen sowohl der Trainings- als auch Validierungsstichproben an. Diese Matrizen liefern uns Indikationen über die Leistungsfähigkeit unseres Klassifikators. Für den Trainingsdatensatz haben wir 77.84 % richtige Antworten, wobei diese Zahl für den Datensatz zur Validierung auf 78 % steigt.
Die nächsten beiden Tabellen zeigen die resultierenden Konfusionsmatrizen sowohl der Trainings- als auch Validierungsstichproben an. Diese Matrizen liefern uns Indikationen über die Leistungsfähigkeit unseres Klassifikators. Für den Trainingsdatensatz haben wir 77.84 % richtige Antworten, wobei diese Zahl für den Datensatz zur Validierung auf 78 % steigt.
Schlussfolgerung zur SVM-Klassifikation
Wir haben unseren Klassifikator mithilfe linearer Kernels trainiert und mit 78 % korrekter Klassifikation ziemlich gute Ergebnisse erhalten. Möglicherweise ist eine geringfügige Anpassung erforderlich, um die besten Datenwissenschaftler auf Kaggle herauszufordern. Ein Ansatz könnte sein, die Kernel-Familie zu ändern und zu sehen, wie gut sich ein höherer Dimensionsbereich auf unserem Datensatz auswirkt.
War dieser Artikel nützlich?
- Ja
- Nein