Classification Naive Bayes dans Excel
Ce tutoriel vous permettra d'exécuter une classification Naive Bayes dans Excel avec XLSTAT. Naive Bayes est un algorithme populaire de machine learning supervisé.
Jeu de données pour la classification Naive Bayes dans Excel avec XLSTAT
Ce tutoriel utilise un jeu de données rendu accessible par le Center for Machine Learning and Intelligent Systems. Leur répertoire en ligne dédié au Machine Learning, accessible à cette adresse rassemble de nombreux jeux de données intéressant relevant du domaine du Machine Learning.
Objectif de ce tutoriel
La méthode de classification naïve bayésienne (Naive Bayes) est un algorithme d’apprentissage automatique supervisé (supervised machine learning) qui permet de classifier un ensemble d’observations selon des règles déterminées par l’algorithme lui-même. Cet outil de classification doit dans un premier temps être entrainé sur un jeu de données d’apprentissage qui montre la classe attendue en fonction des entrées. Pendant la phase d’apprentissage, l’algorithme élabore ses règles de classification sur ce jeu de donnée, pour les appliquer dans un second temps à la classification d’un jeu de données de prédiction.
Dans ce tutoriel, nous utiliserons un jeu de données intitulé Zoo database, créée par Richard Forsyth en 1990 pour illustrer son programme PC-Beagle. Il contient une liste de 101 animaux avec des attributs associés décrit au moyen de 17 variables qualitative distinctes : fourrure, plumes, œufs, lait, aéroporté, aquatique, prédateur, denté, vertébré, respire, venimeux, nageoires, membres inférieurs, queue, domestique, plus grand qu'un chat.
A l'exception de l'attribut "membres inférieurs" qui peut prendre les valeurs 0, 2, 4, 5, 6 et 8, tous les autres variables sont des booléens qui prennent la valeur 1 si l'attribut en question (queue, fourrure, etc. ...) est observé sur l'animal. Enfin, la dernière colonne est un entier prenant des valeurs de 1 à 7 qualifiant le type ou sous-groupe auquel appartient l'animal observé. C'est cette valeur qui constitue la classe que nous souhaitons prédire avec le classifieur bayésien naïf. Pour ce tutoriel, nous divisons en 2 groupes notre jeu de données. Le premier groupe, constitué des 94 premières observations sera utiliser pour la phase d'apprentissage de l'algorithme. Le second, rassemblant les 7 dernières observations constituera le jeu sur lequel le classifieur devra réaliser les prédictions
Paramétrer une classification Naive Bayes dans XLSTAT
Après avoir ouvert XLSTAT, sélectionnez la commande XLSTAT / Machine Learning / classifieur Bayesien Naïf.
La boîte de dialogue du classifieur naïf apparaît.
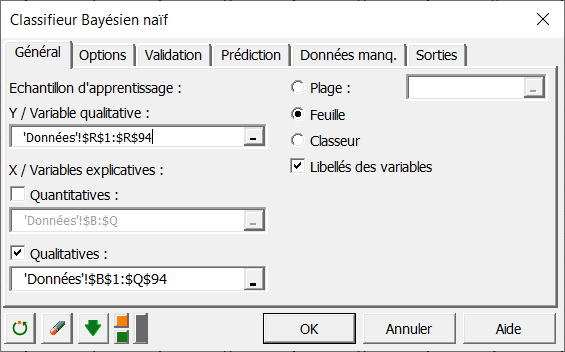
Tout d'abord, sélectionnez la classe de sortie de l'échantillon d'apprentissage dans le champ Y / Variables qualitatives. Dans notre cas, la classe de sortie est le type d'animal listé dans la 18ème colonne du jeu de données Comme précisé ci-dessus, seules les 94 premières lignes sont utilisées comme échantillon d'apprentissage, la sélection doit donc être réalisée en conséquence. Ensuite, il faut sélectionner les X / variables explicatives. Dans notre cas, nous avons uniquement des variables qualitatives. Il faut donc cocher la boîte qualitative et sélectionner les 17 attributs dans le champ correspondant comme montré ci-dessus.
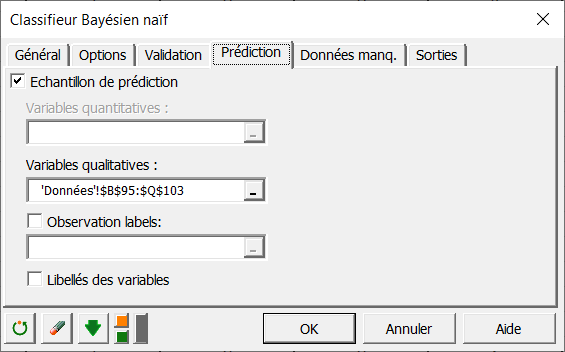
Puis, il faut sélectionner l'échantillon de prédiction qui est constitué des 17 attributs des 7 derniers animaux de la liste.
Dans l'onglet Options, lorsque des variables quantitatives sont utilisées l'utilisateur peut choisir entre plusieurs distributions paramétriques proposées et l'estimation d'une distribution empirique pour calculer la probabilité conditionnelle. Dans le cas de données qualitatives, seul le calcul d'une distribution empirique peut être réalisé et la partie sélection de distribution est désactivée comme montré ci-dessous :
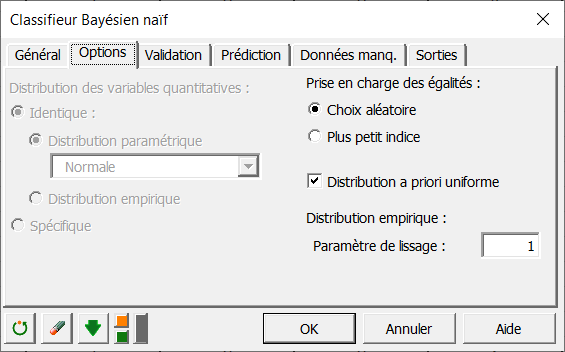
Pour rendre la classification de nouvelles observations plus robuste, il peut être intéressant d'appliquer un lissage de Laplace sur des données qualitatives. Il faut pour cela saisir une valeur supérieure à 0 dans le champ Paramètre de lissage. Pour ce tutoriel, nous allons régler ce paramètre à 1.
Enfin, dans l'onglet Sorties, nous sélectionnons toutes les sorties proposées :
Les calculs démarrent lorsque l'on clique sur OK.
Interpréter les résultats d'une classification Naive Bayes dans XLSTAT
Les deux premiers tableaux présentent les fréquences et fréquences relatives observées pour les classes de sorties et les attributs de l'échantillon d'apprentissage.
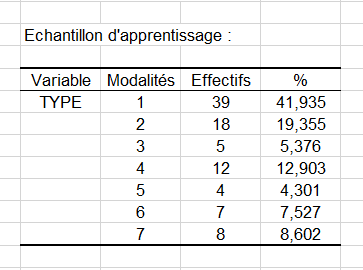 On peut noter dans le premier tableau que la classe de type 1 est de loin la classe la plus fréquemment rencontrée dans le jeu de données avec 41,935% de fréquence d'apparition.
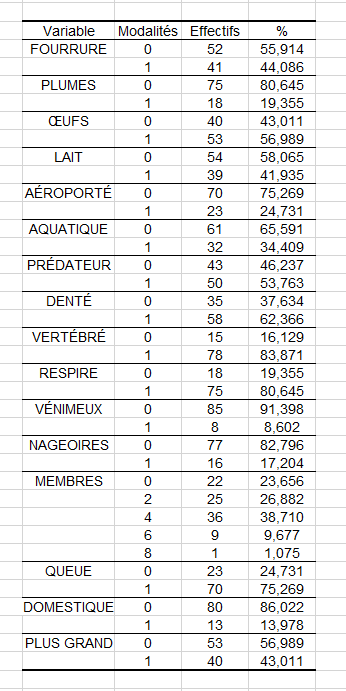
Par ailleurs, nous pouvons voir dans le tableau suivant qu'il n'y a aucune instance d'animal à 5 membres inférieurs dans notre échantillon d'apprentissage.
On peut noter dans le premier tableau que la classe de type 1 est de loin la classe la plus fréquemment rencontrée dans le jeu de données avec 41,935% de fréquence d'apparition.
Par ailleurs, nous pouvons voir dans le tableau suivant qu'il n'y a aucune instance d'animal à 5 membres inférieurs dans notre échantillon d'apprentissage.
 Cependant, dans le tableau présentant les fréquences observées dans le jeu de prédiction, nous pouvons noter la présence d'un animal à 5 pattes :
Cependant, dans le tableau présentant les fréquences observées dans le jeu de prédiction, nous pouvons noter la présence d'un animal à 5 pattes :
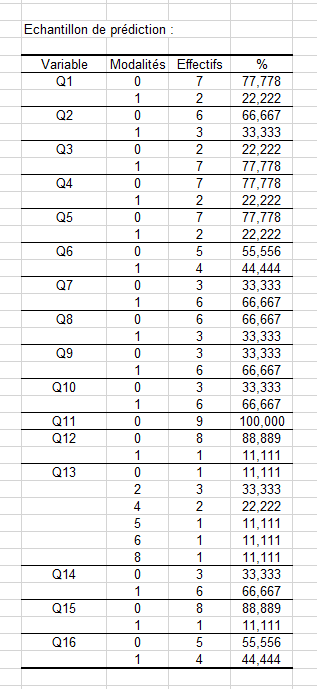 Il sera intéressant de voir comment notre classifieur réagit à cette modalité nouvelle qui n'a jamais été rencontrée durant l'apprentissage.
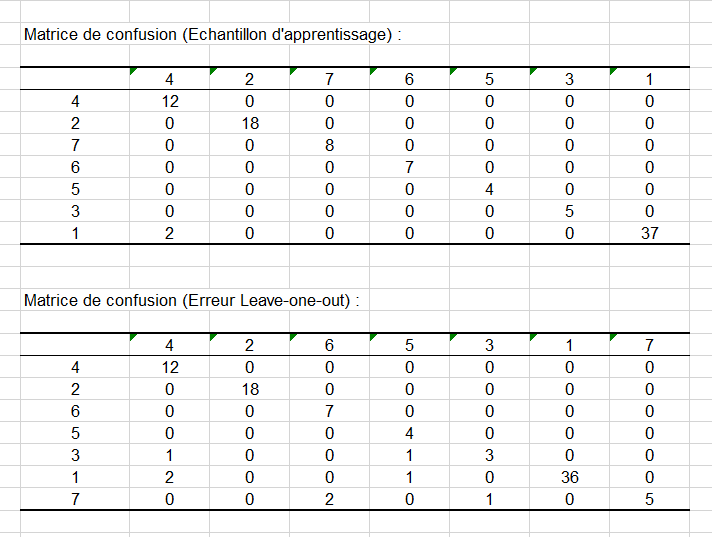
Mais, avant cela, nous pouvons jeter un œil sur les matrices de confusion pour évaluer la robustesse de notre classifieur.
Comme le montre l'image ci-dessous, le classifieur présent un haut taux de réponse positive vraie pour les deux matrices ce qui est très encourageant.
Il sera intéressant de voir comment notre classifieur réagit à cette modalité nouvelle qui n'a jamais été rencontrée durant l'apprentissage.
Mais, avant cela, nous pouvons jeter un œil sur les matrices de confusion pour évaluer la robustesse de notre classifieur.
Comme le montre l'image ci-dessous, le classifieur présent un haut taux de réponse positive vraie pour les deux matrices ce qui est très encourageant.
 Nous arrivons finalement aux résultats de la classification qui sont affichés dans les tableaux ci-dessous:
Nous arrivons finalement aux résultats de la classification qui sont affichés dans les tableaux ci-dessous:
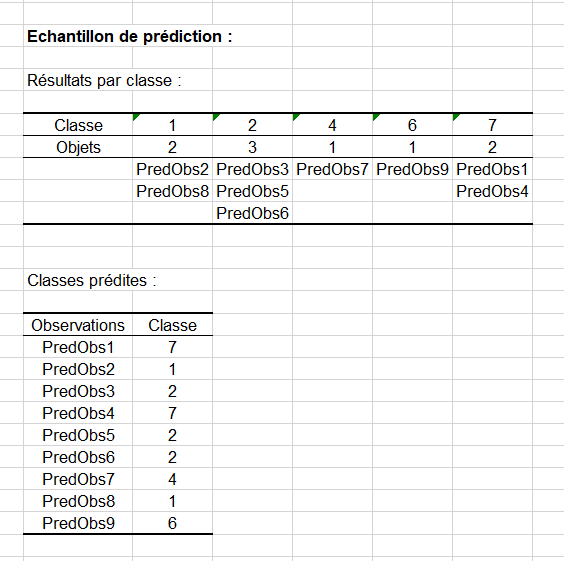
Les résultats sont donnés par classe dans le premier tableau et pour chaque observation dans le second. On peut noter que l'observation intitulée PredObs4 est affecté d'une classe de type 7. C'est l'animal à 5 pattes dont nous avons parlé ci-dessus. C'est une étoile de mer et elle appartient effectivement au type 5, avec le crabe, la palourde et l'écrevisse. Notre classifieur s'est donc bien comporté face à la nouvelle modalité et ceci, grâce au lissage de Laplace.
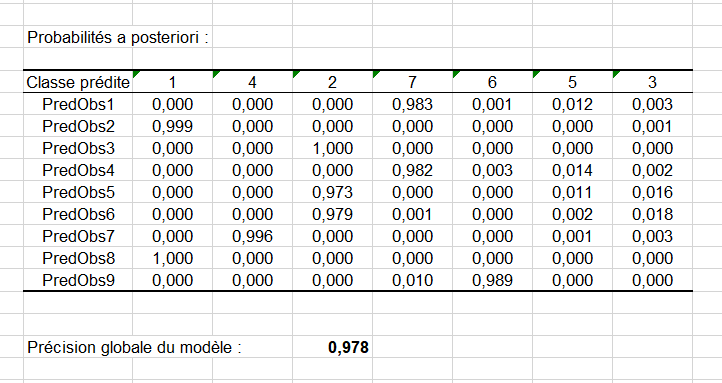
Enfin, les probabilités pour chaque observation dans chaque classe sont affichées dans un dernier tableau récapitulatif :
Cet article vous a t-il été utile ?
- Oui
- Non