Règles d'association, tutoriel dans Excel
Règles d'association
En 1994, Rakesh Agrawal et Ramakrishnan Sikrant ont proposé un algorithme pouvant identifier des associations entre des items sous forme de règles. Cet algorithme est utilisé lorsque le volume de données disponibles est important. Quand le nombre d’items atteint plusieurs dizaines de milliers, la combinatoire ne permet plus de détecter toutes les règles potentielles. Il devient alors nécessaire de restreindre la recherche de règles aux plus importantes. Les mesures de qualité qui en découlent sont probabilistes, ce qui limite l’explosion combinatoire pendant les deux phases de l’algorithme et permet d’ordonner les résultats.
Définitions :
Items : Leur définition dépend du domaine d’application. Ils peuvent constituer des produits, des objets, des patients, des évènements, etc.
Transaction : Un ensemble d’items (minimum 1 item) étiqueté avec un identifiant unique. Les items peuvent appartenir à plusieurs transactions.
Itemset : Un groupe d’items. Les itemsets peuvent appartenir à une ou plusieurs transactions.
Support : Probabilité de retrouver un item ou un itemset X au sein d’une transaction. Elle est estimée par le nombre de fois que l’item ou l’itemset apparaît parmi toutes les transactions disponibles. Elle est comprise entre 0 et 1.
Règle : Une règle définit le lien entre deux itemsets X et Y n’ayant aucun item en commun. X->Y signifie que si X se trouve dans une transaction, Y peut apparaître dans cette même transaction.
Support d’une règle : Probabilité de trouver les items ou itemsets X et Y dans une transaction. Elle est estimée par le nombre de fois que X et Y apparaissent parmi toutes les transactions disponibles. Elle est comprise entre 0 et 1.
Confiance autour d’une règle : Probabilité de trouver l’item ou l’itemset Y dans une transaction, sachant que l’item ou l’itemset X se trouve dans la même transaction. Elle est estimée par la fréquence correspondante observée (nombre de fois que X et Y apparaissent parmi toutes les transactions divisé par le nombre de fois où X est trouvé). Elle est comprise entre 0 et 1.
Lift d’une règle : Le lift d’une règle est le support l’itemset regroupant X et Y divisé par le support de X et le support de Y. Le lift est symétrique (Lift(X->Y)=Lift(Y->X)) et correspond à un nombre réel positif. Un lift supérieur à 1 implique un effet positif de X sur Y (ou de Y sur X) et par, conséquent, une règle significative. Une valeur de 1 signifie qu’il n’y a pas d’effet (indépendance des items ou itemsets). Un lift inférieur à 1 signifie que X a un effet négatif sur Y ou réciproquement (exclusion d’un item ou itemset par l’autre).
Jeu de données
Le jeu de données exploité dans ce tutoriel est un extrait du jeu de données fourni par Tom Brijs (http://fimi.ua.ac.be/data/retail.pdf, T. Brijs, G. Swinnen, K. Vanhoof and G. Wets. The use of association rules for product assortment decisions: a case study. In: Proceedings of the Fifth International Conference on Knowledge Discovery and Data Mining, San Diego (USA), August 15-18, 254-260, 1999). Il comprend des données anonymisées de paniers de consommateurs provenant d’un magasin de détail belge anonyme. Le jeu de données original contient 88163 transactions. Cependant, nous l’avons réduit aux 65000 premières transactions afin que ce tutorial puisse être suivi par des utilisateurs d’Excel 2003. L’outil règles d’association offre aussi la possibilité de travailler sur des fichiers plats contenant plusieurs giga-octets de données, mais l’exemple exploité dans ce tutoriel est basé sur un classeur Excel.
XLSTAT accepte les formats de données suivants :
- Transactionnel : choisissez ce format si vos données sont contenues dans deux colonnes, l'une indiquant la transaction (à sélectionner dans le champ Transactions), l'autre l'item. Typiquement avec ce format, on a une colonne comportant les identifiants de transaction, avec pour chaque transaction, autant de lignes qu'il y a d'items par transaction, et une colonne indiquant les items.
- Liste : choisissez ce format si vos données comprennent une ligne par transaction (les colonnes contenant les noms des items correspondant à la transaction). Le nombre d'items par transaction peut bien entendu varier d'une ligne à l'autre. Le nombre de colonnes de la sélection correspond donc au nombre maximum d'items par transaction.
- Transactions/Variables : choisissez ce format si votre tableau de données correspond à une ligne par transaction et une colonne par variable. Ce format est tel qu'il y a forcément toujours le même nombre d'item par transaction, et que les items d'une même variable ne peuvent pas être présents en même temps.
- Tableau de contingence : choisissez ce format si vos données comprennent une ligne par transaction et une colonne par item avec pour chaque transaction des valeurs nulles si l'item n'est pas présent et une valeur positive s'il est présent.
Dans ce tutoriel, les données sont disponibles au format liste, où chaque ligne représente une transaction. Il y a autant de colonnes que d’items par transaction.
Paramétrer une analyse de règles d’association
Une fois XLSTAT lancé, choisir la commande XLSTAT / Machine Learning / Règles d’association, ou cliquer sur le bouton correspondant dans la barre d’outils XLSTAT.

Une fois le bouton cliqué, la boîte de dialogue apparait. Sélectionner les données sur la feuille Excel. Dans la case Items, sélectionner les colonnes A à BV contenant toutes les transactions et les items (afin d’identifier la dernière colonne contenant une transaction, presser Ctrl Fin, ce qui déplacera le curseur en bas à droite du tableau). L’option Libellés inclus est inactivée car la première colonne des données sélectionnées ne contient pas de libellés.
Conserver la valeur par défaut pour le support minimal. Les règles ayant un support inférieur à cette valeur ne seront pas prises en compte.
Conserver la valeur par défaut pour la confiance minimale. Les règles ayant un support inférieur à cette valeur ne seront pas prises en compte.
Conserver la valeur par défaut pour le nombre minimum d’antécédents. Il n’existe pas de contrainte spécifique sur le nombre d’items compris dans la partie gauche (X) de la règle (X->Y).
Dans l’onglet Options, nous optons pour un tri des règles suivant le critère de confiance.
Les calculs démarrent dès que vous cliquez sur le bouton OK. Ils durent 35 secondes environ. Une fenêtre vous permettant d’arrêter l’analyse à tout moment apparait. Puis les résultats s’affichent.
Interpréter les résultats d'une analyse de règles d'association
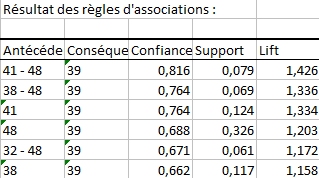
Les premiers résultats confirment le nombre d’items et le nombre de transactions dans le jeu de données. Le tableau de résultat des règles d’associations affiche toutes les règles respectant les contraintes paramétrées au sein de l’onglet Général de la boîte de dialogue. La règle ayant la meilleure confiance est celle indiquant que si les produits 41 et 48 se trouvent dans le panier, alors il y a 81.6% de chance que le produit 39 s’y trouve aussi. Cette règle a été détectée dans 7.9% des transactions. La valeur de lift de 1.426 signifie que la présence des produits (41 et 48) dans une transaction augmente la chance d’avoir le produit 39 dans la même transaction avec un facteur de 1.426, et réciproquement.
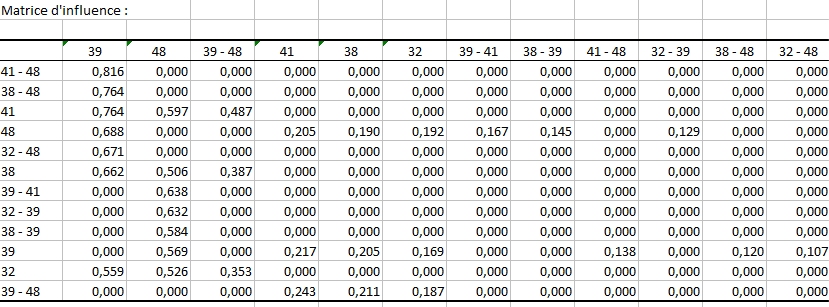
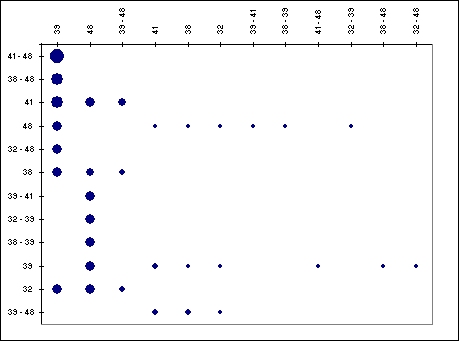
La matrice d’influence est une autre manière d’afficher les confiances de détection des items (placés en colonnes) sachant que les items en lignes sont présents.
Le graphique qui suit résume l’information contenue dans la matrice d’influence.
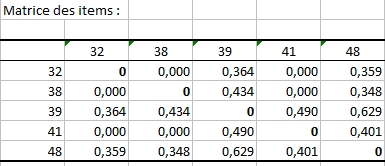
Le tableau suivant est une matrice symétrique résumant les confiances entre produits impliqués dans les règles respectant les critères de support et de confiance minimaux. Ce tableau est utilisé par la suite pour créer une visualisation des produits basé sur leurs proximités et centrée sur la méthode MDS. Cette fonctionnalité unique a été développée par Addinsoft en 2014.
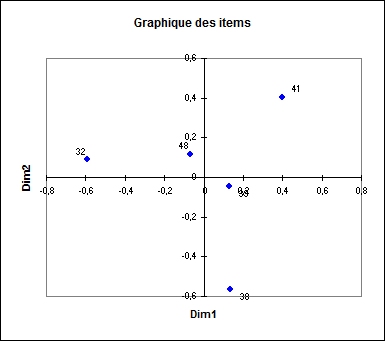
Le graphique des items montre que les produits 49 et 39 sont les plus proches.
En somme, nous avons utilisé les règles d’association afin d’analyser des paniers de consommateurs. L’interprétation et les décisions opérationnelles découlant de ces résultats dépendent fortement de l’expertise que l’utilisateur possède du marché et des produits mis en jeu.
Cet article vous a t-il été utile ?
- Oui
- Non