Generalisierte Procrustes-Analyse in Excel
Dieses Tutorium zeigt Ihnen, wie Sie eine generalisierte Procrustes Analyse - GPA - in Excel mithilfe der Statistiksoftware XLSTAT durchführen und interpretieren.
Was ist eine generalisierte Procrustes-Analyse (GPA)?
Die generalisierte Procrustes Analyse (GPA) wird häufig zur sensoriellen Analyse vor einer Präferenzkartographie (Preference mapping) eingesetzt zum Beispiel um die Skaleneffekte zu reduzieren und zu einer Konsenskonfiguration zu gelangen. Sie kann er ebenfalls erlauben die Proximität von bestimmten Ausdrücken durch verschiedene Experten eingesetzt zu analysieren.
Datensatz für eine generalisierte Procrustes Analyse
Die Daten dieses Tutoriels entsprechen einer Studie, in der ein Produktmarketingteam bestimmen möchte, wie vier sehr verschiedene Käsearten bewertet werden. Zehn Experten wurden gebeten, die vier Käsearten mehrmals (ohne Kenntnis der Käseart) nach den drei folgenden Kriterien: Säuregehalt, Fremdheit, Härte. Die hier verwendeten Werte entsprechen den Mittelwerten der Bewertungen für jeden Käse und jeden Experten.
Absicht dieser generalisierten Procrustes Analyse
Ziel ist es, die Daten so zu transformieren, dass die Skaleneffekte (einige Experten könnten einen weiter gefassten Wertebereich nutzen) oder Positionseffekte (einige Experten könnten dazu neigen, eher den oberen oder unteren Wertebereich der Skala) entfernt werden, um eine Konsenskonfiguration zu erhalten, die anschließend in einem externen Präferenz-Mapping benutzt werden können.
Einrichten einer generalisierten Procrustes Analyse
Nach dem Start von XLSTAT wählen Sie den XLSTAT / Zeitreihenanalyse / GPA oder Multibloc Datenanalyse / GPA Befehl.
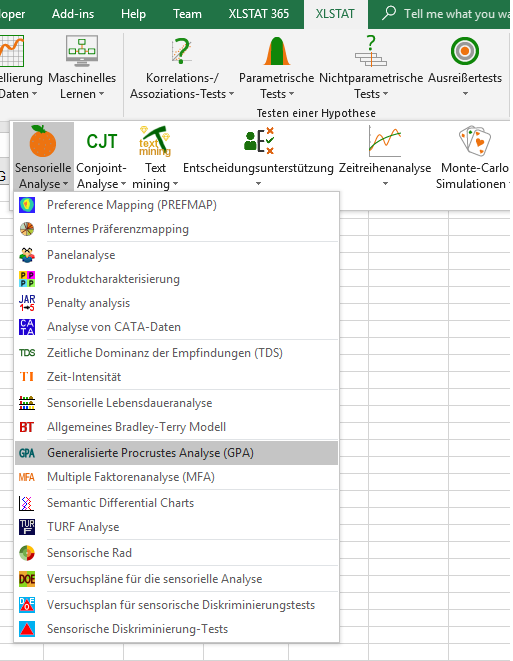
Nach dem Klicken des Buttons, erscheint das Dialogfenster. Wählen Sie nun die Daten, die den Konfigurationen entsprechen (eine Konfiguration entspricht hier einem Satz von Bewertungen eines Experten). Die Anzahl der Konfigurationen muss eingegeben werden. Das wir 10 Experten haben, geben wir 10 ein. Da jeder Experte 3 Bewertungen für jede der drei Dimensionen gab, können wir XLSTAT mitteilen, dass die Anzahl der Dimensionen konstant ist, dem die „gleich“ Option aktiviert wird. Falls die Anzahl der Dimensionen verschieden für mindestens eine der Konfigurationen ist, so müssen Sie eine Spalte mit der Anzahl an Dimensionen für jede der Konfigurationen.
Um die Darstellung der Ergebnisse besser zu gestalten, wurden ebenfalls Konfigurationsbeschriftungen und die Objektbeschriftungen (in unserem Fall die Käsearten) ausgewählt.
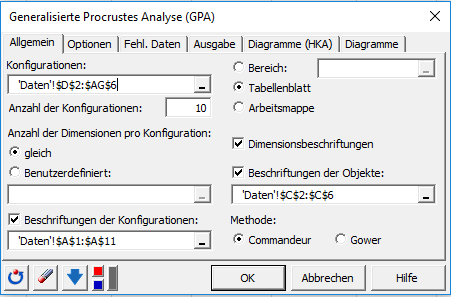
Die folgenden Optionen wurden ausgewählt.
Nach dem Klicken auf den OK Button, beginnen die Berechnungen und die Ergebnisse werden auf einem neuen Excel-Blatt angezeigt.
Interpretieren der Ergebnisse einer generalisierten Procrustes Analyse
Das erste Ergebnis ist die PANOVA-Tabelle, die die Effizienz jeder GPA Transformation in Bezug auf die Reduktion der Gesamtvariabilität beurteilt. Man kann sehen, dass die Skalentransformation am effizientesten ist (kleinster p-value).

Die zweite Tabelle und das zugehörige Diagramm geben die Residuen je Objekt nach den Transformationen an. Man kann sehen, dass der C3 Käse die kleinsten Residuen hat. Die deutet an, dass darin höchstwahrscheinlich ein Konsens zwischen den zwischen den Experten besteht.

Die dritte Tabelle und das zugehörige Diagramm geben die Residuen je Konfiguration nach den Transformationen an. Man kann sehen, dass der Experte2 das größte Residuum aufweist und damit Bewertungen gaben, die nicht dem Konsens entsprechen.

Die nächste Tabelle und das zugehörige Diagramm geben die Skalenfaktoren der GPA Transformationen an. Ein Faktor kleiner 1 gibt an, dass der zugehörige Experte den Wertebereich breiter als seine Kollegen benutzt hat. Man kann sehen, dass die Experten 1 und 3 dazu neigen, schmaller die Noten zu verteilen, als die übrigen Experten.

Anschließend wird ein Konsenstest durchgeführt, um zu beurteilen, ob die Konsenskonfiguration ein wirklicher Konsens ist. Dieser Permutationstest erlaubt es zu bestimmen, ob der beobachtete Rc-Wert (Rc entspricht dem Verhältnis der Ausgangsvarianz erklärt durch die Konsenskonfiguration) signifikant größer als 95% der Ergebnisse ist, die beim durchführen der Permutationsfällen erhalten werden.


Ein weiterer Permutationstest wird benutzt, um zu überprüfen, wie viele Dimensionen zur Anzeige berücksichtigt werden sollten. Man kann hier sehen, dass für die dritte Dimension der F Wert unterhalb des 95. Perzentils liegt. Daher kann man schließen, dass zwei Dimensionen ausreichen.

Die nächsten Ergebnisse entsprechen den Ergebnissen des HKA-Schritts (nicht standardisierte HKA). Während die GPA bereits einen Rotationsschritt für jede Konfiguration beinhaltet, damit diese die Konsenskonfiguration am besten trifft, so entspricht die HKA hier der optimalen Transformation der Konsenskonfiguration unter den gewohnten HKA Bedingungen. Die HKA Transformation wird dann auf jede Konfiguration entsprechend dem zugehörigen Experten angewandt.
Die Eigenwerte zeigen, wie viel der Variabilität den einzelnen Achsen entspricht. Hier sind 99% der Variabilität auf den ersten beiden Achsen dargestellt. Falls die Variabilität zwischen den Experten aufgeteilt ist, sieht man, dass die Ergebnisse fast für alle Experten gleich sind..


Die Ergebnisse sind in die Ergebnisse, die der Konsenskonfiguration entsprechen und die den Ergebnissen für jede einzelne Konfiguration entsprechen, aufgeteilt. Die Objektkoordinaten der Konsenskonfiguration könnten später in einer PREFMAP Analyse als Produktkoordinaten in der Präferenzkarte benutzt werden.
Im Korrelationskreis kann man sehen, dass die „Fremdheit“ meist auf der negativen Seite der ersten Achse zu finden ist, dass der „Säuregehalt“ und die „Härte“ oft gemischt sind. Die Fremdheit im Ursprung des Diagramms entspricht dem 6. Experten, der die Produkte in Bezug auf dieses Kriterium nicht bewertete.

Die nächsten beiden Diagramme sind die Objektkarte, die entsprechend den Konfigurationen und den Objekten eingefärbt ist (siehe unten). Die Punkte sind alle nah bei der ersten Achse, da diese 96% der Variabilität auf sich vereinigt und da XLSTAT orthonormale Karten anzeigt, um Missinterpretationen zu vermeiden.


Im das Diagramm lesbarer zu gestalten, kann man die Skalenoptionen ändern (wie man es mit jedem beliebigen Excel-Diagramm durchführen kann — Sie können dies ebenfalls mit dem XLSTAT AxesZoomer durchführen). Man erhält die folgende Karte:

Man kann sehen, dass zwischen den Käsearten C1 und C3 auf der Karte klar unterschieden werden kann, währen die Grenze zwischen den Produkten C2 und C4 nicht sehr klar ist. Dies bedeutet, dass die Experten gut zwischen C1 und C3 unterscheiden, dass ein Konsens für diese Produkte besteht und dass sie nicht klar zwischen C2 und C4 unterscheiden.
War dieser Artikel nützlich?
- Ja
- Nein