Analyse de données de préférences dans Excel
Ce tutoriel explique comment réaliser et interpréter une analyse de données de préférences avec Excel en utilisant XLSTAT.
Jeu de données pour une analyse de données de préférences
Les données proviennent d’une étude de préférences sur 5 pommes. Ces dernières ont été évaluées par 119 consommateurs.
But de ce tutoriel
Le but de ce tutoriel est :
-
de déterminer les pommes les plus appréciées.
-
de comparer les pommes deux à deux.
-
de déterminer si les sujets sont en accord
Nous utiliserons la fonction Analyse de données de préférences de XLSTAT pour faire cette analyse. Cet outil nous permettra de réaliser les trois objectifs définis ci-dessus.
Paramétrer la boîte de dialogue de l’Analyse de données de préférences
Une fois XLSTAT lancé, sélectionnez le menu XLSTAT / Fonctions avancées / Analyse de données sensorielles / Analyse de données de préférences.

La boîte de dialogue Analyse de données de préférences apparaît.

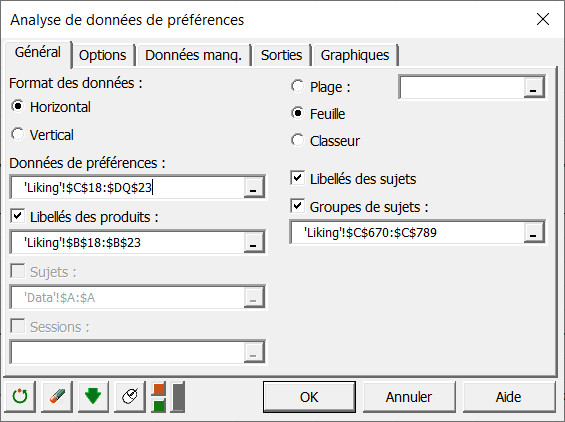
Dans l’onglet Général, vous pouvez alors sélectionner les données de préférences. Les libellés des produits (pommes) et des sujets doivent également être renseignés dans ce format.
Dans l’onglet Options, nous avons décidé de centrer les sujets pour éviter l’effet des sujets ayant tendance à mettre de meilleures notes d’appréciation que d’autres. De plus, nous avons demandé une classification de ces derniers.

Les calculs commencent lorsque vous cliquez sur le bouton OK.
Interpréter les résultats d’une analyse de données de préférences
La première étape concerne la visualisation et l’analyse avant de centrer les sujets. Un des résultats pouvant retenir notre attention est la moyenne des sujets avant de centrer (ce résultat n’est pas affiché après le centrage puisque par définition les moyennes des sujets seront ramenées à 0). Nous voyons que certains sujets ont clairement tendance à donner de meilleures notes que d’autres, et que le centrage est donc nécessaire.

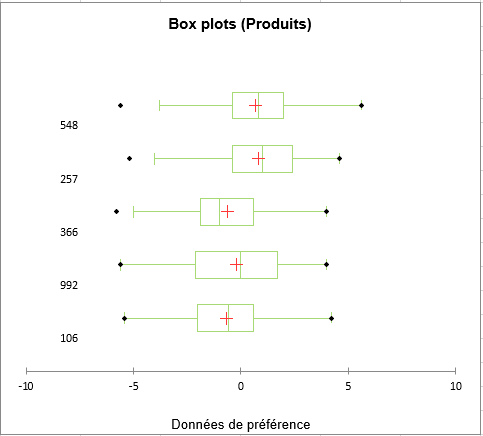
À la suite du centrage des sujets, nous pouvons nous intéresser aux box plots des produits. Ces derniers permettent d’évaluer la dispersion des données de préférences pour chacune des pommes. Nous voyons ici que la pomme 992 a été sujette à plus de différences de notations que les autres, puisque son écart interquartile est plus important.
Le tableau suivant est le résultat de l’analyse de la variance (ANOVA) avec les données de préférences en variable dépendante et les produits en facteur. Ce dernier permet de déterminer qu’il y a au moins un produit qui possède une moyenne de préférences différente des autres.

Afin de déterminer les différences entre ces produits, nous pouvons nous attarder sur les graphiques de moyennes suivants. Il s’avère clairement que nous avons deux groupes de produits, avec les pommes 257 et 548 qui sont plus appréciées que les pommes 106, 366 et 992.

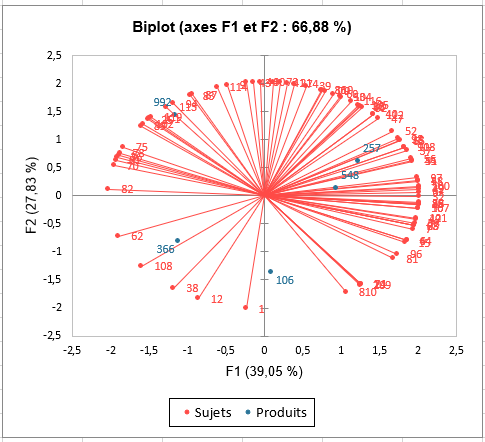
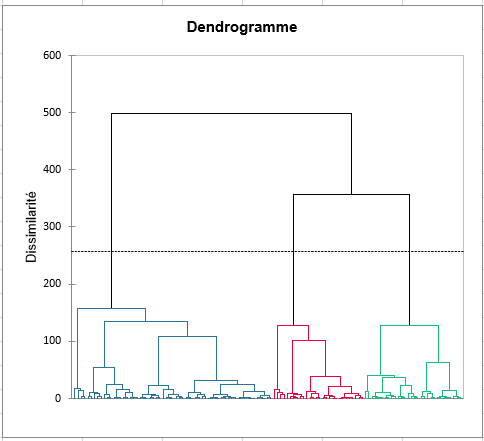
La cartographie interne des préférences permet de déterminer sujet par sujet quels sont les produits les plus aimés. Et si, comme les résultats précédents l’indiquent, les produits 257 et 548 sont les plus appréciés, nous voyons que nous sommes loin d’être dans le cas d’un consensus (les sujets sont très dispersés). Par conséquent, une classification des sujets est une bonne idée pour étudier d’éventuels groupes de sujets. Cette dernière nous suggère de considérer 3 groupes de sujets.
Analyser les différences entre les groupes de sujets
La comparaison de groupes de sujets est courante en analyse sensorielle. Si nous allons ici appliquer les résultats de la classification, elle est aussi très souvent réalisée sur des groupes connus a priori (hommes et femmes par exemple). Pour la réaliser nous sélectionnons les données au format horizontal dans le champ « Données de préférences » et nous sélectionnons les classes des sujets dans le champ « Groupes de sujets ».

L’analyse est dans un premier temps réalisée groupe par groupe, et nous pouvons par exemple nous focaliser sur les moyennes des produits dans chaque groupe. Nous pouvons voir que le dernier groupe n’apprécie pas la pomme 257 au contraire des deux autres mais apprécie plus la pomme 366. Le second groupe se distingue notamment par le fait de ne pas apprécier la pomme 992.

De plus, une comparaison produit par produit est réalisée à la fin de l’analyse. Par exemple, pour le cas de la pomme 106, l’ANOVA nous indique qu’il y a une différence significative d’appréciation entre les groupes, et le graphique des moyennes nous indique que le groupe 1 est différent des deux autres.


Pour conclure, nous avons commencé par analyser nos données de préférences de manière globale. Puis, après avoir remarqué que les avis des sujets différaient, nous avons utilisé les résultats de la classification de ces derniers pour réaliser des comparaisons entre groupes de sujets.
Cet article vous a t-il été utile ?
- Oui
- Non