Analyse STATIS dans Excel, tutoriel
Ce tutoriel vous aidera à mettre en place et interpréter une analyse STATIS dans Excel avec le logiciel XLSTAT.
Jeu de données à analyser avec STATIS
Un classeur Excel comprenant à la fois les données utilisées dans cet exemple et les résultats obtenus peut être téléchargé.
Les données proviennent d’un projective mapping/Napping réalisé à Rennes par AGROCAMPUS OUEST. 24 sujets ont placé 8 smoothies sur une nappe. Ainsi, une personne trouvant 2 produits similaires les placera proches sur la nappe, et les produits perçus différemment seront éloignés. Le projective mapping (ou Napping) donne ainsi une notion de distance entre les produits. Pour l'analyse des données, les coordonnées de chaque nappe sont récupérées. Le fichier original peut être obtenu avec le package R SensoMineR.
Le but de ce tutoriel est d’étudier et visualiser les liens entres les smoothies ainsi que de déterminer les accords entre les sujets.
Qu’est-ce que la méthode STATIS ?
La méthode STATIS est l'une des méthodes d'analyse de données multi configurations les plus utilisées en analyse sensorielle. Les configurations sont alors les différents assesseurs, sujets ou juges. Cette méthode peut notamment être utilisée dans le cas de données de projective mapping/Napping, profil conventionnel et profil libre.
Le grand intérêt de STATIS réside dans le fait que les configurations atypiques ont un poids plus faible que ceux qui sont centraux à l'ensemble des configurations. L'analyse reflète donc au mieux le point de vue général et non celui des configurations atypiques.
Paramétrer une analyse STATIS avec XLSTAT
Une fois XLSTAT lancé, choisissez XLSTAT/Fonctions avancées/Analyse de données multiblocs/STATIS.
 Une fois le bouton cliqué, la boite de dialogue STATIS apparaît.
Une fois le bouton cliqué, la boite de dialogue STATIS apparaît.
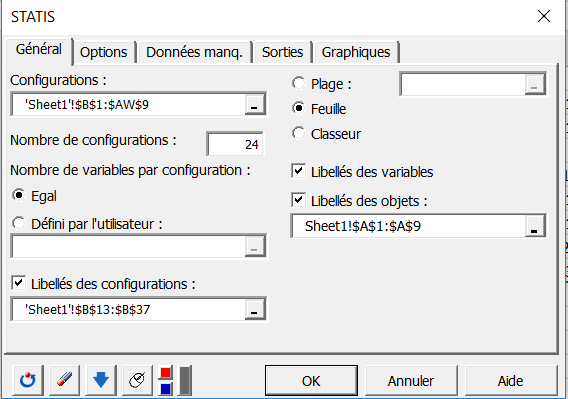 Vous pouvez alors sélectionner les configurations (une configuration correspond ici à l'ensemble des coordonnées données par un sujet).
Vous pouvez alors sélectionner les configurations (une configuration correspond ici à l'ensemble des coordonnées données par un sujet).
Le nombre de configurations doit ensuite être saisi. Il y a ici 24 tableaux contigus correspondant aux 24 sujets.
Comme les 24 configurations ont chacune deux variables, l'option Egal est choisie pour le nombre de variables. Lorsque le nombre de variables varie pour les différentes configurations, il faut sélectionner une colonne contenant le nombre de variables des différentes configurations.
Les étiquettes des configurations et des produits sont aussi sélectionnées donc il faut sélectionner les options Libellés des configurations et Libellés des objets (dans notre cas les smoothies).
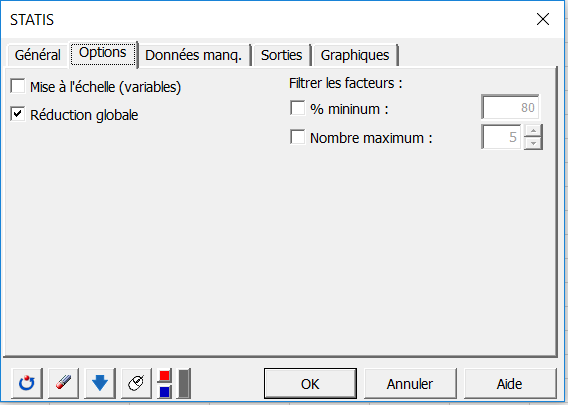
Dans l’onglet Options, nous avons choisi de réduire globalement les configurations pour ne pas donner d’effet d’échelle. A l’intérieur de chaque configuration, toutes les variables étant sur la même échelle, il n’est pas donc nécessaire de réduire les variables.
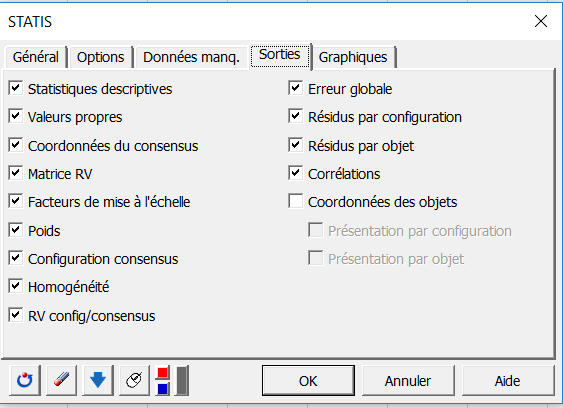
 Dans l’onglet Sorties, nous avons choisi d’afficher la matrice RV ainsi que le RV entre les configurations et le consensus pour avoir des indicateurs de proximité entre les sujets.
Dans l’onglet Sorties, nous avons choisi d’afficher la matrice RV ainsi que le RV entre les configurations et le consensus pour avoir des indicateurs de proximité entre les sujets.
 Les calculs commencent lorsque vous cliquez sur le bouton OK.
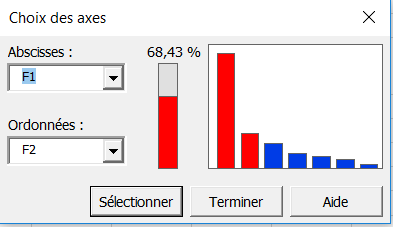
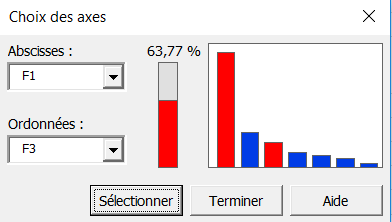
Une nouvelle boîte vous permet de choisir les axes pour lesquels les graphiques doivent être affichés. Dans notre cas, le pourcentage de variabilité représenté sur les deux premiers axes n'est pas particulièrement élevé (68.43%) ; pour éviter une mauvaise interprétation des graphiques, un affichage sur les axes 1 et 3 est donc aussi demandé.
Les calculs commencent lorsque vous cliquez sur le bouton OK.
Une nouvelle boîte vous permet de choisir les axes pour lesquels les graphiques doivent être affichés. Dans notre cas, le pourcentage de variabilité représenté sur les deux premiers axes n'est pas particulièrement élevé (68.43%) ; pour éviter une mauvaise interprétation des graphiques, un affichage sur les axes 1 et 3 est donc aussi demandé.
Interpréter les résultats d’une analyse STATIS
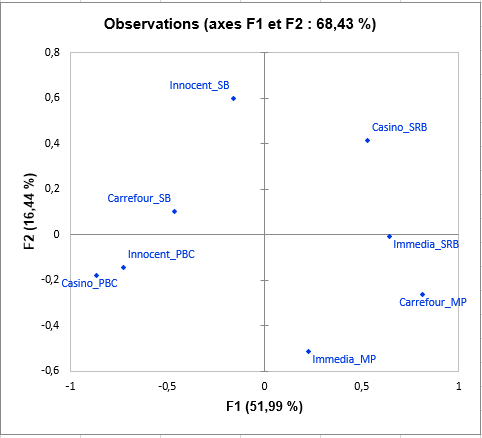
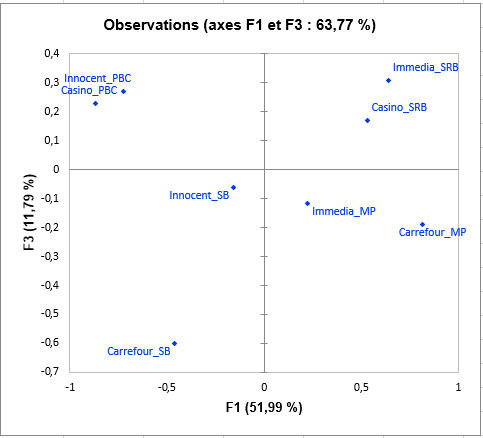
Le graphique suivant est l’objectif principal de STATIS : représenter les observations sur une carte à 2 dimensions, et ainsi identifier les proximités. Nous voyons par exemple que les smoothies « Casino_PBC » et « Innocent_PBC » sont perçus comme proches, mais qu’ils diffèrent beaucoup du « Casino_SRB ». Sur la troisième dimension, nous pouvons voir que Carrefour_SB est totalement opposé à « Casino_PBC », « Innocent_PBC », « Immedia_SRB » et « Casino_SRB ».
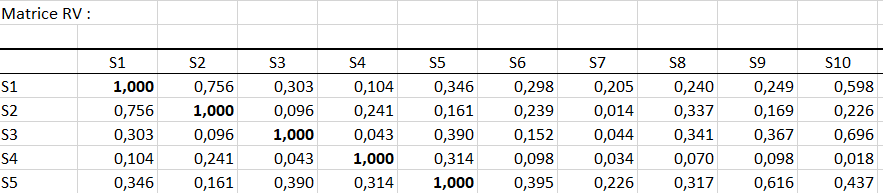
 Si l’on s’intéresse à deux sujets en particulier, il est utile de regarder la matrice RV qui donne le coefficient RV entre chaque sujet (coefficient entre 0 et 1, qui augmente avec la proximité des sujets). Nous voyons ici que le sujet 1 a un avis très similaire au sujet 2, mais très différent du sujet 4 (qui a des faibles valeurs de RV avec beaucoup d’autres sujets ici).
Si l’on s’intéresse à deux sujets en particulier, il est utile de regarder la matrice RV qui donne le coefficient RV entre chaque sujet (coefficient entre 0 et 1, qui augmente avec la proximité des sujets). Nous voyons ici que le sujet 1 a un avis très similaire au sujet 2, mais très différent du sujet 4 (qui a des faibles valeurs de RV avec beaucoup d’autres sujets ici).
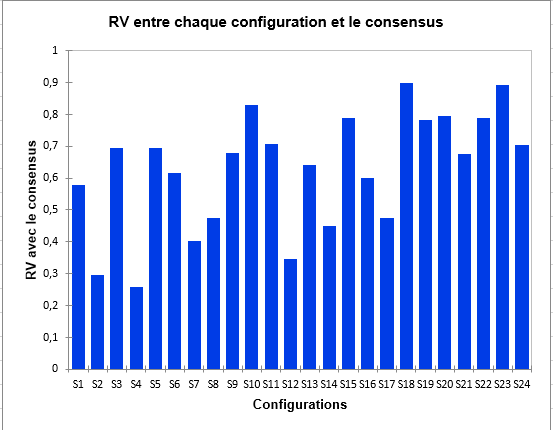
 Il peut être très important d’évaluer la proximité d’un sujet avec tous les autres, c’est-à-dire avec le point de vue global reflété par le consensus. Pour cela, nous regardons le diagramme en bâtons suivant, et nous voyons que le sujet 4 est un sujet plutôt atypique, au contraire du 18 ou du 23.
Il peut être très important d’évaluer la proximité d’un sujet avec tous les autres, c’est-à-dire avec le point de vue global reflété par le consensus. Pour cela, nous regardons le diagramme en bâtons suivant, et nous voyons que le sujet 4 est un sujet plutôt atypique, au contraire du 18 ou du 23.
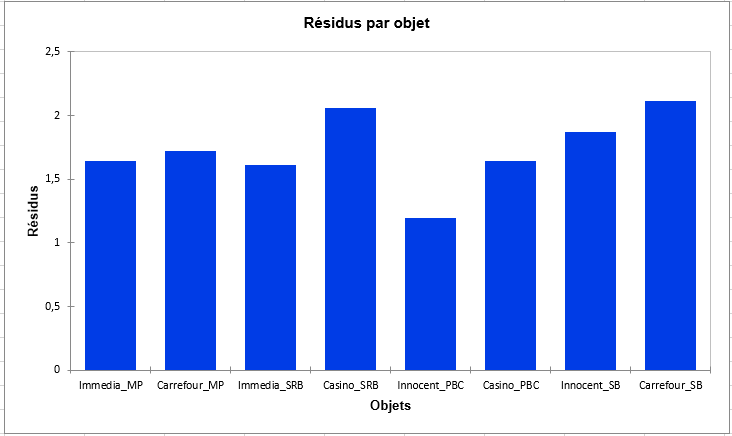
 Enfin, le graphique suivant donne les résidus par objet, qui indique quels objets ont été placés plutôt de même manière par les sujets, comme le smoothie « Innocent_PBC », ou plutôt différemment, comme le smoothie « Carrefour_SB ».
Enfin, le graphique suivant donne les résidus par objet, qui indique quels objets ont été placés plutôt de même manière par les sujets, comme le smoothie « Innocent_PBC », ou plutôt différemment, comme le smoothie « Carrefour_SB ».
Cet article vous a t-il été utile ?
- Oui
- Non