ANALYSE DE DONNÉES CATA (CHECK-ALL-THAT-APPLY) DANS EXCEL
Ce tutoriel vous aidera à configurer et à interpréter une analyse CATA dans Excel à l'aide du logiciel de statistiques XLSTAT.
Jeu de données pour l’analyse de données CATA avec XLSTAT
Pour ce tutoriel, nous utiliserons des données fournies par Ares et al. (2014). Elles correspondent au jugement de 6 produits (5 produits réels et un idéal) par 119 consommateurs et sur 15 attributs. Les données sont enregistrées avec un format binaire (0 : attribut non coché ; 1 : attribut coché). Puis chaque consommateur donne une note d’appréciation (0-10) à chaque produit, à l’exception du produit idéal.
Les données sont disposées avec un format vertical, ce qui signifie qu’il y a une ligne par combinaison de consommateur et de produit.
But de ce tutoriel sur l’analyse de données CATA avec XLSTAT
L’objectif de ce tutoriel est d’effectuer une analyse CATA (Check-All-That-Apply) afin de caractériser des produits testés par des consommateurs.
Mise en place d’une analyse CATA avec XLSTAT
-
Pour réaliser une analyse CATA, cliquez sur Sensoriel / Données CATA / Analyse des données CATA.
-
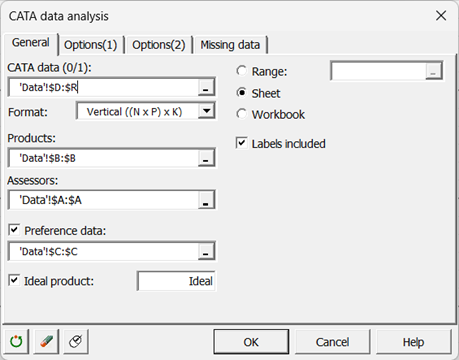
Dans l'onglet Général, assurez-vous d'abord de sélectionner le format de données Vertical.
-
Dans le champ Données CATA, sélectionnez la table des attributs.
-
Ensuite, sélectionnez les colonnes Consommateur, Échantillon et Préférence dans les champs Évaluateurs, Produits et Données de préférence, respectivement.
-
Saisissez l'identifiant du produit idéal dans le champ Produit idéal.
Important : Le jeu de données doit être équilibré (un évaluateur par produit).
-
Dans l'onglet Options(1), sélectionnez la distance du Chi-deux pour l'Analyse des Correspondances, la validation des données CATA et l'Indépendance des attributs.
-
Cliquez sur le bouton OK.
-
Une boîte de dialogue apparaît pour sélectionner et valider les axes à afficher sur la représentation graphique de l'analyse des correspondances. Il suffit de cliquer sur le bouton Terminé.
Interpréter les résultats d’une analyse CATA avec XLSTAT - première partie
Les deux premiers tableaux et graphiques sont relatifs à la validation des données CATA. Tout d’abord, une détection des sujets ayant cochés bien plus ou bien moins que les autres est réalisée. Dans notre cas, la majorité des sujets ont coché entre 20% et 35% du temps, mais certains ont un comportement particulier. Par exemple, le sujet 27 n’a coché que 7% du temps ! Une analyse similaire relative aux attributs est ensuite réalisée, permettant de détecter les attributs sur-utilisés ou sous-utilisés.
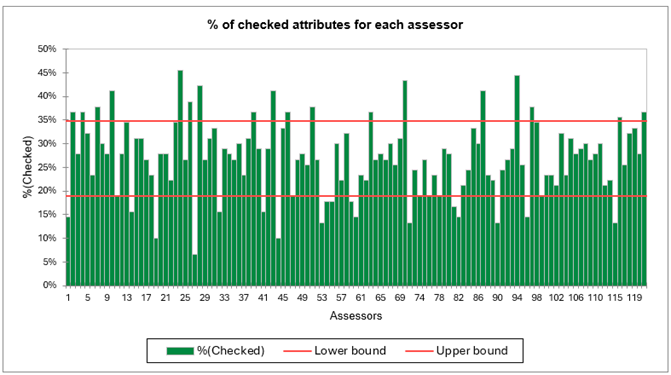
Ensuite, une analyse regroupant les deux précédentes est réalisée. Elle indique le pourcentage de cochages par sujet et par attribut. Cette analyse permet de déterminer si les attributs sont cochés de manière consensuelle ou non. L’attribut Juteux est notamment sujet à des contrastes, avec certains sujets qui le cochent plus de 80% du temps et d’autres moins de 20%.

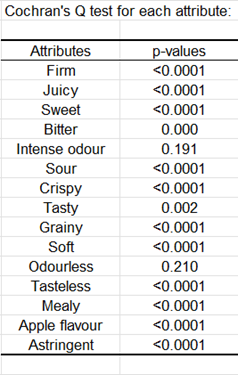
Pour un attribut donné, le test Q de Cochran permet de tester l’effet d’une variable explicative (Produit) sur la validation ou la non-validation de l’attribut par les consommateurs. Une p-value se trouvant en dessous du seuil de significativité indique que les produits sont significativement différents les uns des autres. Si tel est le cas, nous pouvons nous intéresser aux comparaisons multiples par paires représentées par les petites lettres à l’intérieur des cellules du tableau :
-
deux produits partageant la (les) même(s) lettre(s) ne sont pas significativement différents.
-
deux produits n’ayant aucune lettre en commun sont significativement différents.
A l’exception des attributs relatifs à l’odorat (sans odeur et odeur intense), tous les attributs sont associés à des p-values significatives au seuil 0.05. Par exemple, si on considère l’attribut Croustillant, c'est le produit 257 qui est le plus coché. Cependant, il n’est pas significativement plus croustillant que le 548 (cf. lettres). Les produits 992 et 366 sont les moins croustillants et ne sont pas significativement différents l’un de l’autre.
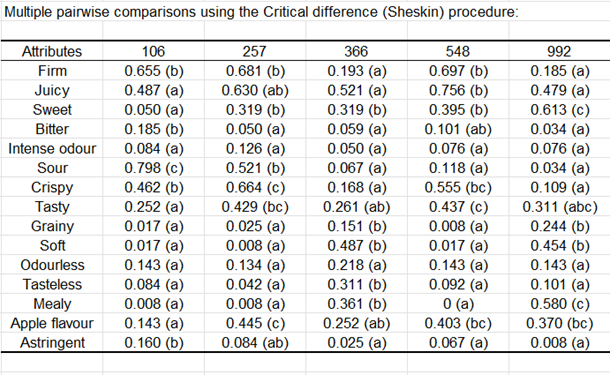
Pour chacun des produits, un test d’indépendance des attributs est réalisé pour déterminer si ces attributs ne sont pas redondants. Ainsi, nous pouvons voir que pour le produit 106, les attributs Juteux et Ferme sont redondants.
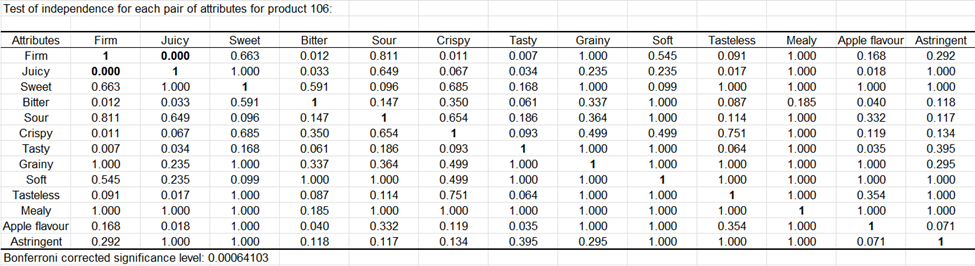
La table de contingence qui suit correspond à une somme des tableaux d’attributs, sujet par sujet. Elle est utilisée pour effectuer une analyse factorielle des correspondances (AFC).
Le test d’indépendance entre les lignes et les colonnes est réalisé (résultat disponible pour l’AFC classique uniquement (utilisant la distance du Khi²)). La p-value étant inférieure au niveau de signification (0.05), nous pouvons conclure qu’il y a une forte probabilité pour que de vraies différences existent entre les produits.
La table des valeurs propres et le graphique correspondant permettent de vérifier la qualité de l’analyse. La qualité de l’analyse est bonne (92.17% d’inertie expliquée sur les deux premières dimensions).
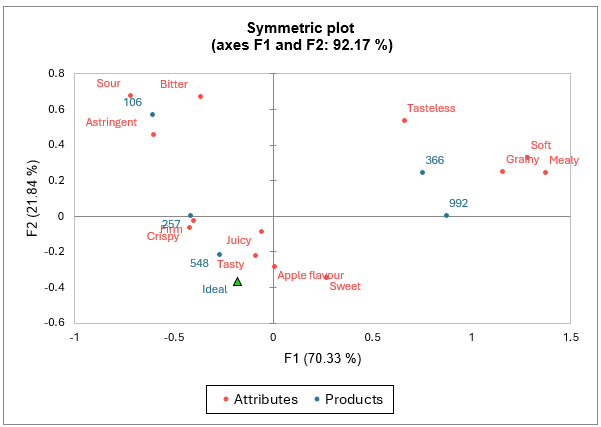
Selon le plan de projection, un produit idéal doit être relativement savoureux, juteux, croustillant, ferme, sucré et doit avoir un goût de pomme. Par ailleurs, il ne devrait pas être trop aigre, amer, astringent, granuleux, doux, farineux, et sans goût. Le produit 548 semble se rapprocher le plus du produit idéal, alors que le produit 106 en est loin à cause de son amertume, son aigreur et son astringence. Les produits 366 et 992 sont également relativement éloignés du produit idéal.
Pour plus d’information sur l’analyse factorielle des correspondances, cliquez ici.
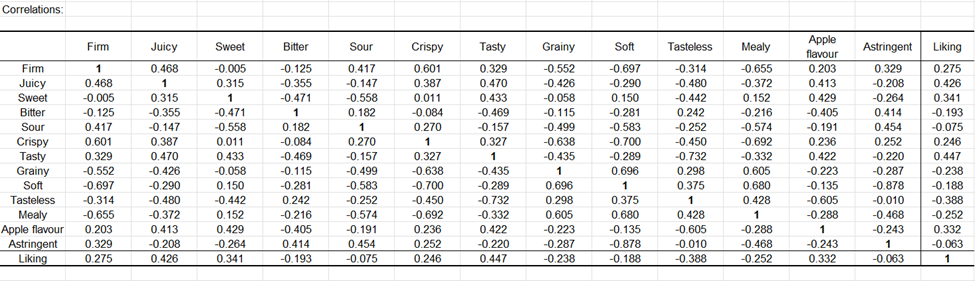
Le résultat qui suit est une matrice des corrélations contenant les attributs (corrélations tétrachoriques) et les données de préférence (corrélations bisérielles, dernière ligne). La matrice contient quelques corrélations fortes. La corrélation négative entre aigre et sucré indique que lorsque les sujets cochent l'attribut sucré, ils cochent rarement l'attribut aigre, et vice-versa. Les scores d'appréciation semblent positivement (même si légèrement) corrélés aux attributs liés au produit idéal dans l'analyse des correspondances (juteux, savoureux, goût de pomme).
Les corrélations sont analysées par Analyse en Coordonnées Principale (PCoA) et les résultats sont représentés sur un plan de projection. Le Scree plot montre que les deux premières dimensions sont suffisantes pour interpréter les relations entre attributs. On retrouve ici l’appréciation liée aux attributs juteux, savoureux et goût de pomme.
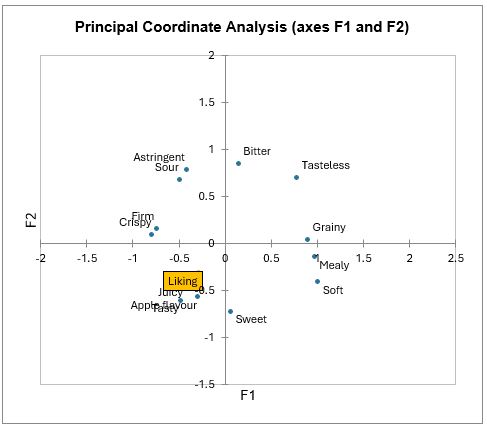
Pour plus d’informations sur l’Analyse en Coordonnées Principales, veuillez cliquer ici.
Interpréter les résultats d’une analyse CATA avec XLSTAT - deuxième partie
Lorsque des données d’appréciation sont disponibles, les résultats qui suivent sont ceux de l'analyse des pénalités.
Une première analyse, basée sur les cas pour lesquels l’attribut est coché pour le produit idéal mais pas pour le produit réel, permet d’identifier les attributs nécessaires. Un tableau de comparaison contient les fréquences d’apparition de P(Non)|(Oui) et P(Oui)|(Oui) pour chaque attribut. Le graphique qui suit permet de visualiser ces fréquences ainsi que les pourcentages d’occurrence de ces deux situations.
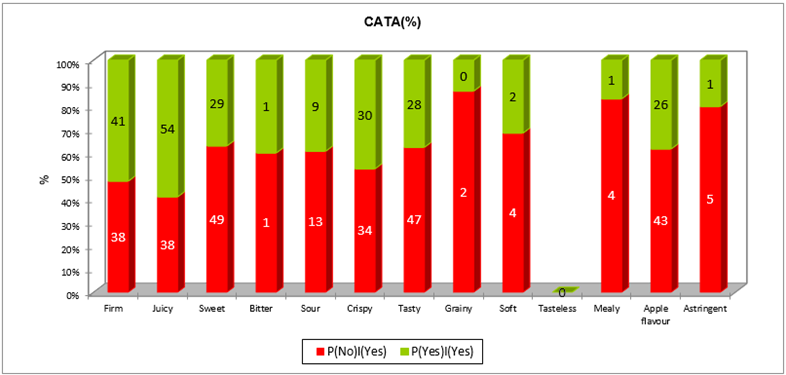
Les différences de moyenne d’appréciation entre les deux situations sont présentées pour chaque attribut et leur significativité est testée. Par exemple, l’attribut ferme implique une augmentation de 1.5 points d’appréciation entre les produits réels et le produit idéal. Cette augmentation est significative à 0.05 (p < 0.0001).
Remarque : si aucun produit idéal n’a été évalué, cette analyse est remplacée par l’analyse de présence et absence des attributs.
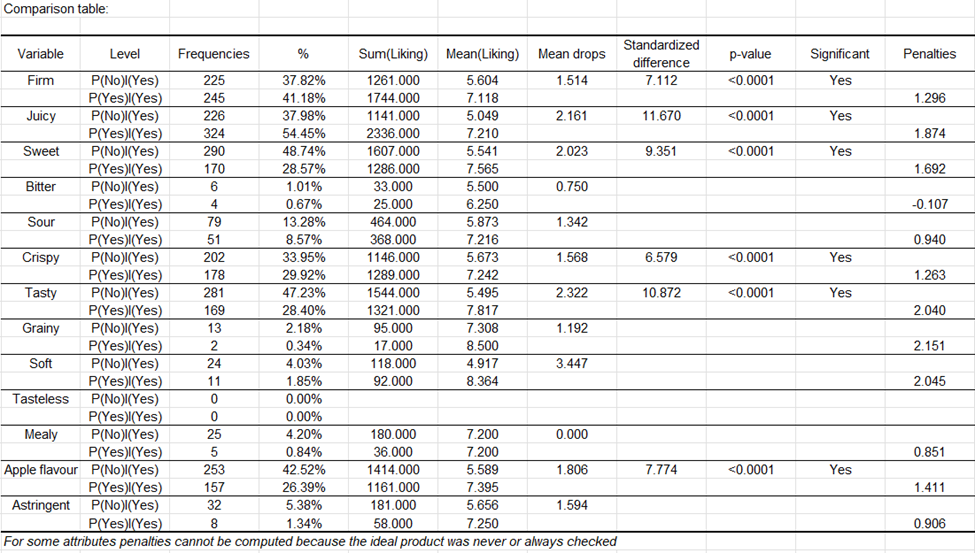
Le graphique des effets sur la moyenne contient les attributs avec un effet sur la moyenne significatif. Les augmentations de moyenne sont représentées en bleu et correspondent aux attributs nécessaires, les chutes de moyenne sont représentées en rouge.
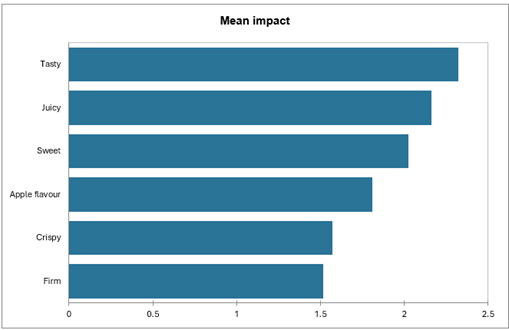
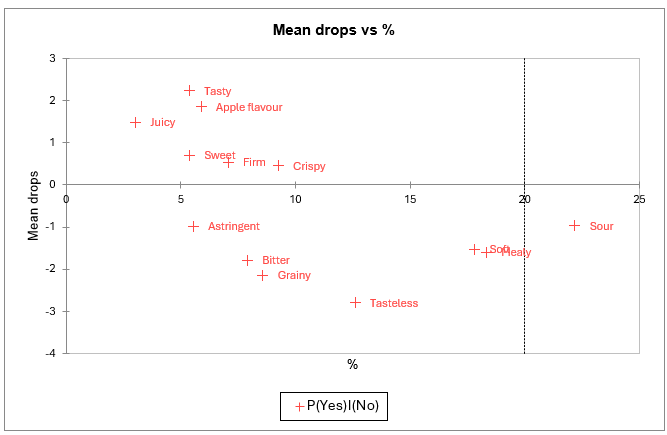
Le graphique Effets sur la moyenne vs % permet d’identifier clairement les attributs nécessaires.
-
L’axe des Y correspond aux différences d'appréciation des produits quand les sujets ont coché à la fois un produit et le produit idéal (cellule [1,1] du tableau "analyse des attributs") et quand ils n'ont coché que le produit idéal (cellule[0,1]).
-
L’axe des X représente le pourcentage d’entrées incluant un cochage du produit idéal sans que le produit réel ne soit coché, ce qui correspond à une situation où l’attribut décrit bien le produit idéal mais est relativement peu ressenti dans les produits réels.
Ainsi, les attributs associés à des coordonnées élevées sur les deux axes (savoureux, sucré, juteux, goût de pomme, croustillant, ferme) apparaissent là encore en tant que nécessaires.
Une deuxième analyse, similaire à la première mais basée sur les cas pour lesquels l’attribut est coché pour le produit réel mais pas pour le produit idéal, permet d’identifier les attributs intéressants.
Remarque : cette analyse n’est effectuée que quand un produit idéal a été évalué.
Le graphique des effets sur la moyenne contient les attributs avec un effet sur la moyenne significatif. Les augmentations de moyenne sont représentées en bleues et correspondent aux attributs intéressants, les chutes de moyennes sont représentées en rouge et correspondent aux attributs négatifs. Ici, seul l'attribut Aigre a pu être analysé.
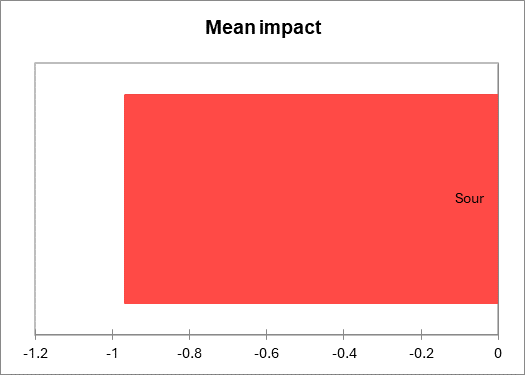
Le graphique Effets sur la moyenne permet d’identifier clairement les attributs négatifs et les attributs intéressants.
-
L’axe des Y correspond aux différences d'appréciation des produits quand les sujets n'ont coché ni le produit idéal ni le produit (cellule [0,0] du tableau "analyse des attributs") et quand ils ont coché le produit (cellule [1,0]).
-
L’axe des X représente le pourcentage d’entrées incluant un cochage du produit réel sans que le produit idéal ne soit coché, ce qui correspond à une situation où l’attribut décrit bien les produits réels mais est relativement peu coché pour le produit idéal.
Ainsi, les attributs associés à une coordonnée basse sur l’axe des Y (astringent, amer, granuleux, sans goût, doux, farineux et aigre) apparaissent là encore en tant que négatifs. Les attributs associés à une coordonnée forte sur l’axes des Y sont intéressants.
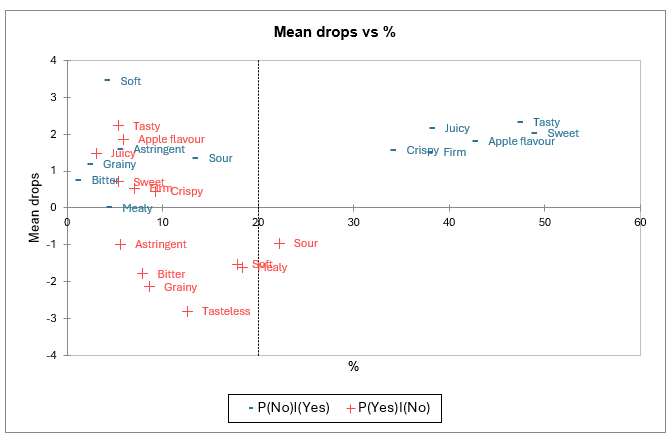
Les deux analyses présentées ci-dessus sont ensuite résumées sur un plan de projection. Ici encore, savoureux, sucré, goût de pomme, ferme, croustillant et juteux apparaissent comme nécessaires, et Aigre apparaît comme négatif.
Ensuite, une série de tableaux 2x2 (un tableau par attribut) est affichée. En lignes, les valeurs enregistrées pour le produit idéal ; en colonnes, les valeurs obtenues pour les produits testés. Les cellules du tableau contiennent les préférences moyennes (moyennées sur les sujets et les produits) et le % de tous les cas associés à la combinaison correspondante de 0s et/ou de 1s.
Pour un attribut donné, si l’attribut est coché pour le produit idéal (seconde ligne), et si la préférence pour les produits cochés (cellule [1,1]) est significativement supérieure à la préférence pour les produits non cochés (cellule [1,0]), alors l’attribut est nécessaire.
Symétriquement, si l’attribut n’est pas coché pour le produit idéal (première ligne) et si la préférence pour les produits non cochés (cellule [0,0]) est significativement supérieure à la préférence pour les produits cochés (cellule [0,1]), alors l’attribut est négatif.
Si (cellule [0,1]) > (cellule [0,0]) significativement, alors l'attribut est intéressant. Si l’attribut n’est pas coché pour le produit idéal (première ligne), qu’il n’est ni négatif ni intéressant, et si la préférence pour les produits cochés (cellule [0,1]) est comparable à celle pour les produits non cochés (cellule [0,0]) alors l’attribut est indifférent.
XLSTAT considère deux produits comparables si la valeur absolue de leur différence est inférieure à un. Enfin, si l’attribut n’est pas nécessaire et que la préférence pour les produits cochés (cellule [1,1]) est comparable à celle pour les produits non cochés (cellule [1,0]), l’attribut est sans influence.
Certains tableaux peuvent correspondre à 3 situations. XLSTAT tentera d’associer chaque tableau 2x2 à une situation en le reliant à une des règles définie plus haut, dans le même ordre.
Il est à noter que pour prendre une décision concernant un attribut, XLSTAT vérifiera que la taille seuil pour la population que vous avez indiqué dans la boite de dialogue (Options 2) est bien respectée.
Par exemple, pour l’attribut « Ferme», 41% des entrées relatives aux produits, excepté le produit idéal, sont cochées pour le produit en question et pour le produit idéal à la fois. La moyenne de l’appréciation pour ces entrées est de 7.1.

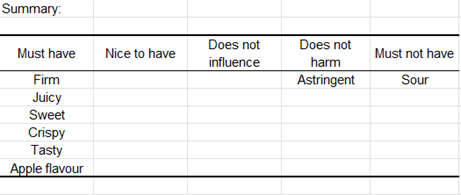
Dans le tableau final de synthèse, nous remarquons que 6 attributs parmi les 15 sont nécessaires, 1 attribut est indifférent et 1 attribut est négatif. Les autres attributs n'ont pu être reliés à aucune règle de décision.
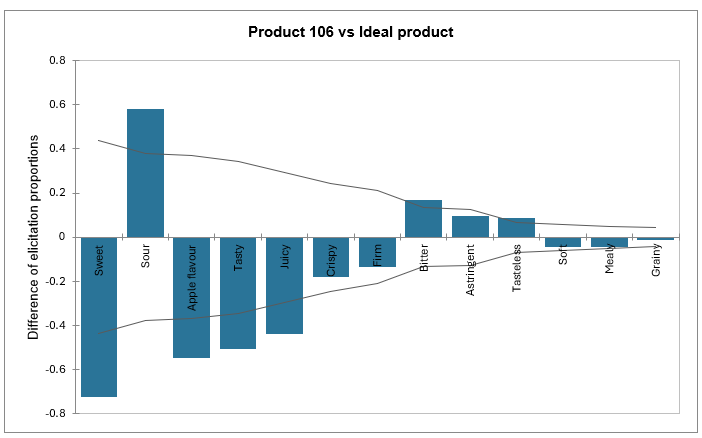
Enfin, vous pouvez visualiser une représentation graphique de la différence de citation pour chaque produit par rapport à l'idéal.
Pour chaque attribut, nous pouvons voir si le produit est semblable ou différent du produit idéal. Plus un attribut est sujet à des différences, plus il est problématique et se situera à gauche du graphique. À l'inverse, plus pour un attribut donné le produit est semblable au produit idéal, plus la ligne sera proche de 0. Si la différence est négative, l'attribut n'est pas assez présent, alors que si elle positive, il est trop présent.
Pour terminer, l'intervalle de confiance permet de déterminer si la différence avec le produit idéal est significative.
Dans cet exemple, la valeur représentée par la première barre du graphique 'Produit 106 vs Produit idéal' peut être calculée comme suit : (6/119) – 92/119) = 0,0504 – 0,7731 = -0,7227.
Pour aller plus loin
Découvrez une autre méthode pour analyser les ensembles de données CATA disponibles dans XLSTAT : CATATIS. Pour classifier les consommateurs avec des données CATA, veuillez utiliser la méthode CLUSCATA.
Cet article vous a t-il été utile ?
- Oui
- Non